摘要
Scikit-Learn 是机器学习领域中非常著名的一个类库,其中封装了很多机器学习中需要使用到的算法工具。Scikit-Learn 构建在 NumPy 和 SciPy 等常见的数据科学类库之上。其核心算法使用更底层的语言实现,通过 Python 进行调用。
1. 基本介绍
1.1. 环境
导入相关类库:
1 |
|
1.2. 算法
Scikit-Learn 包含机器学习领域中比较主流的算法,包括:
Supervised learning
- Linear model (Ridge, Lasso, Elastic Net, …)
- Support Vector Machine
- Tree-bassed methods (Random Forests, Bagging, GBRT, …)
- Nearest neighbors
- Neural networks (basics)
- Gaussian Processes
- Feature selection
Unsupervised learning
- Clustering (KMeans, Ward, …)
- Matrix decomposition (PCA, ICA, …)
- Density estimation
- Outlier detection
Model selection and evaluation
- Cross-validation
- Grid-search
- Lost of metrics
等等
1.3. 数据集
1.3.1. 鸢尾花数据
右加州大学开放的用于机器学习测试的清洗好的数据集,鸢尾花数据集,包含三种不同类型的鸢尾花,特征包含鸢尾花花瓣和花萼的长度和宽度。
导入数据:
1 | dataset = pd.read_csv('./input/Iris.csv') |
打印结果:
1 | pandas.core.frame.DataFrame |
数据是 DataFrame 类型,然后查看一下数据内容:
1 | print(dataset.head()) |
打印结果:
| df_index | Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
拆分训练集和测试集,加载的数据集的特征和标签是在一起的,但是在使用算法训练模型时,需要将特征和标签拆分开来,同时还需要拆分训练集和测试集。
1 | X = dataset.iloc[:, :-1].values |
首先将特征和输入拆分,这里 [:, :-1] 中的第一个冒号表示的是所截取的行,开始到结束都是空的,也就是截取所有,而第 :-1 表示要截取的列,是从开始到最后第二列,也就是特征了。对应的 y 截取的是最后一列,也就是标签了。
然后使用 sklearn 中的方法来拆分训练集和测试集。
1 | from sklearn.model_selection import train_test_split |
这里 test_size 是 0.2 表示训练集和测试集是 8:2,random_state 表示随机数的种子,每次拆分如果使用相同的种子,那么就会得到两组相同的随机数。种子还可以设置为 None,那么每次得到的随机数种子也是随机的。
1.3.2. 构造数据集
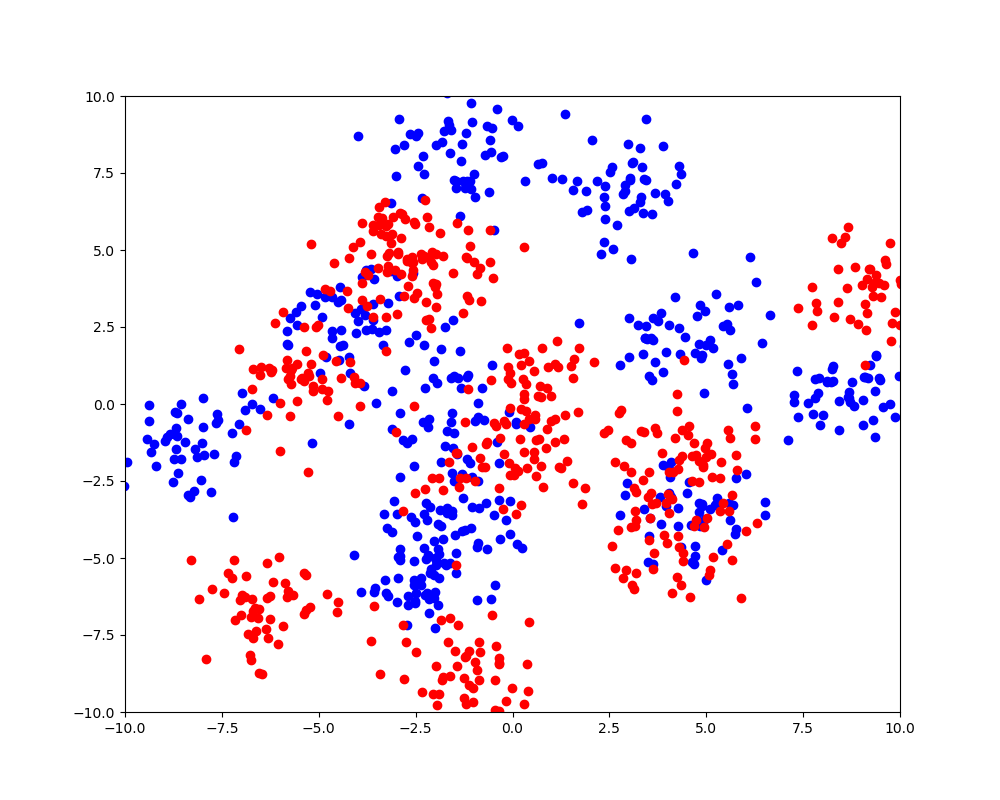
这里使用 make_blobs 来生成测试数据。这是一个聚类数据生成器。这个方法会生成一个包含若干个中心点的分类数据、中心点个数、特征数量、样本条数等都是可以指定的。
1 | from sklearn.datasets import make_blobs |
打印的特征:
| df_index | 0 | 1 |
|---|---|---|
| 0 | -6.452556 | -8.763583 |
| 1 | 0.289821 | 0.146772 |
| 2 | -5.184123 | -1.253470 |
| 3 | -4.713888 | 3.674405 |
| 4 | 4.515583 | -2.881380 |
打印的标签:
| df_index | 0 |
|---|---|
| 0 | r |
| 1 | r |
| 2 | b |
| 3 | r |
| 4 | b |
绘制散点图看看:
1 | from matplotlib import pyplot as plt |
效果如下:
1.4. 接口
Scikit-Learn 中所有的学习算法采用类似的 API 设计,每个学习算法都包含以下一些接口:
- 一个用于构建和拟合模型的接口
- 一个用于进行预测的接口
- 一个用于转换数据的接口
2. K-Nearest Neighbours
在机器学习中,KNN 算法是一种无参的分类和回归算法。在 KNN 分类中采用多数投票制,邻居进行投票,占多数的那个即为这个对象的分类。如果是回归,那么结果就是其最近的几个邻居的平均值。
下面使用 KNN 对鸢尾花数据进行模型训练和评估:
1 | from sklearn.neighbors import KNeighborsClassifier |
这里使用 KNeighborsClassifier 进行分类,设置近邻数量为 n_neighbors=8。然后用 fit() 方法训练模型,使用 predict() 方法预测结果。
然后使用 accuracy_score() 函数计算评分。评分结果:
1 | accuracy is 1.0 |
除了准确率,还可以使用混淆矩阵观察预测效果:
1 | from sklearn.metrics import confusion_matrix |
打印结果:
1 | [[11 0 0] |
此外,还可以查看准确率、召回率等指标:
1 | from sklearn.metrics import classification_report |
打印结果:
| - | precision | recall | f1-score | support |
|---|---|---|---|---|
| Iris-setosa | 1.00 | 1.00 | 1.00 | 11 |
| Iris-versicolor | 1.00 | 1.00 | 1.00 | 13 |
| Iris-virginica | 1.00 | 1.00 | 1.00 | 6 |
| micro avg | 1.00 | 1.00 | 1.00 | 30 |
| macro avg | 1.00 | 1.00 | 1.00 | 30 |
| weighted avg | 1.00 | 1.00 | 1.00 | 30 |
3. Radius Neighbors Classifier
有限半径的近邻分类。在 sklean 中 RadiusNeighborsClassifier 与 KNeighborsClassifier 非常相似,除了两个参数。第一个参数是 RadiusNeighborsClassifier 需要指定固定半径,并使用在这个半径区域内的近邻进行分类。第二个参数用来表明在指定半径区域内,哪一个标签是不应该出现的,如果该区域内出现这个标签对应的输入,那么这个输入就是异常值。
1 | from sklearn.neighbors import RadiusNeighborsClassifier |
评分结果:
1 | accuracy is 1.0 |
4. Logistic Regression
Logistic Regression 也是一种回归分析,并且其因变量是只有两种可能性。Logistic Regression 是一种使用非常广泛的分类算法,很多复杂的方法都基于这个方法。
1 | from sklearn.linear_model import LogisticRegression |
评分结果:
1 | accuracy is 0.933333333333 |
5. Passive Aggressive Classifier
Passive Aggressive Classifier 是一种增量学习算法,当训练数据比较大时,可以一次只传入部分训练数据进行训练,不同的迭代传入训练数据。使用 partial_fit() 方法进行增量训练,不过这里实例只是简单用法。
1 | from sklearn.linear_model import PassiveAggressiveClassifier |
评分结果:
1 | accuracy is 0.7 |
6. Naive Bayes
在机器学习中,Naive Bayes 是一种基于贝叶斯定律的分类器,它假设特征之间都是相互独立的。
1 | from sklearn.naive_bayes import GaussianNB |
评分结果:
1 | accuracy is 1.0 |
7. BernoulliNB
适合二分类问题的分类器。
1 | from sklearn.naive_bayes import BernoulliNB |
评分结果:
1 | accuracy is 0.2 |
8. SVM
支持向量机,一种适合处理高维度数据的算法。在数据的特征数量比数据的样本数据量还大的时候仍然有效。它可以使用样本集中的一部分进行计算,也就是可以完全在内存中计算。此外,用户还可以自定义核函数。
1 | from sklearn.svm import SVC |
评分结果:
1 | accuracy is 1.0 |
9. Nu-Support Vector Classification
类似于 SVM,但是可以使用一个参数指定参与计算的支持向量的数量。
1 | from sklearn.svm import NuSVC |
评分结果:
1 | accuracy is 1.0 |
10. Linear Support Vector Classification
指定线性核的 SVM 分类器。
1 | from sklearn.svm import LinearSVC |
评分结果:
1 | accuracy is 0.8 |
11. Decision Tree
决策树是一种无参的监督学习方法,可以用来解决分类或回归问题。
1 | from sklearn.tree import DecisionTreeClassifier |
评分结果:
1 | accuracy is 0.966666666667 |
12. ExtraTreeClassifier
一种随机树分类器。其与决策树的主要区别在于树的构建过程。
1 | from sklearn.tree import ExtraTreeClassifier |
评分结果:
1 | accuracy is 1.0 |
13. Neural network
多层感知机。
1 | from sklearn.neural_network import MLPClassifier |
评分结果:
1 | accuracy is 0.933333333333 |
14. RandomForest
随机森林通过基于不同的训练样本子集来训练出许多决策树分类器,然后使用这些决策树的平均值来进行预测。
1 | from sklearn.ensemble import RandomForestClassifier |
评分结果:
1 | accuracy is 1.0 |
15. Bagging classifier
Bagging classifier 通过随机子集训练处众多分类器,然后将所有分类器的结果进行聚合,得到最终的预测结果。
1 | from sklearn.ensemble import BaggingClassifier |
评分结果:
1 | accuracy is 0.966666666667 |
16. AdaBoost classifier
AdaBoost classifier 首先在原始的数据集上拟合一个分类器,然后利用第一个分类器分类的结果训练第二个分类器,并且调整其中错误分类的权重,这样子分类器就会关注更难以分类的那部分数据集。
1 | from sklearn.ensemble import AdaBoostClassifier |
评分结果:
1 | accuracy is 0.966666666667 |
17. Gradient Boosting Classifier
1 | from sklearn.ensemble import GradientBoostingClassifier |
评分结果:
1 | accuracy is 0.966666666667 |
18. Linear Discriminant Analysis
Linear Discriminant Analysis 和 Quadratic Discriminant Analysis 是两种经典的分类方法,如两个方法的名字所示,一个是使用一条直线进行分类,一个是使用一个二次决策曲面进行分类。
1 | from sklearn.discriminant_analysis import LinearDiscriminantAnalysis |
评分结果:
1 | accuracy is 1.0 |
19. Quadratic Discriminant Analysis
1 | from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis |
评分结果:
1 | accuracy is 1.0 |
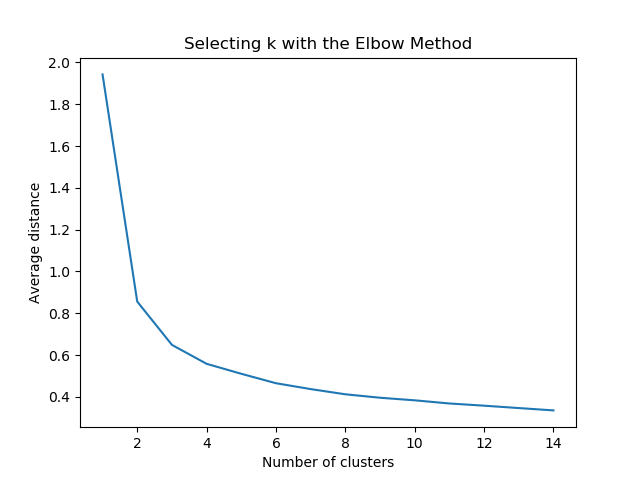
20. Kmeans
Kmeans 是一种无监督学习,用来处理未分类数据。其目标是利用算法从数据中找出分组,然后将数据划分到各个分组中,分组的数量是不一定的。
1 | from sklearn.cluster import KMeans |
设置分组的数量从 1 - 15,根据分组数量以及分组之间的距离判断应该设置的合适的分组数量。