摘要
本文通过一个 Kaggle 的入门级项目泰坦尼克生存预测,介绍一个一般性的数据科学项目工程框架。该框架涵盖一般数据科学问题解决方案的几个主要过程。包括定义问题、收集数据、准备数据、探索性分析、处理模型、验证和优化。
项目介绍
项目描述
在1912年4月15日发生的泰坦沉船事件中,2224名乘客和船员中,有1502人丧生。在这次海难中导致如此多人员丧生的一个重要原因是没有足够的救生船。不过其中一些乘客的存活率要比其他乘客的存活率大,比如妇女/儿童和上层乘客。
在这个挑战中,我们期望你分析一下什么样的座次有利于提高存活率。并且,我们要求你应用机器学习工具来预测哪些用户在此次海难中存活下来。
评价
目标
预测在海难中存活的乘客。对给定测试集中的乘客ID,预测一个 0 或 1 的值表示其存活情况。
度量标准
准确预测乘客存活情况的百分比。我们使用“准确率”来表示。
提交文件格式
提交一份包含 418 条数据和一个标题行的 CSV 文件。如果提交的文件中有多于的行或列,回报错。
文件应该正好只有两行:
1、PassengerId:乘客ID,任意顺序
2、Survived:存活情况,1表示存活,0表示丧生
1 | PassengerId,Survived |
数据
数据被分为两组:
1、训练集(train.csv)
2、测试集(test.csv)
训练集
用来构建你的机器学习模型。在这个训练集中,我们为每个乘客ID提供了一个对应的结果,用于表示这位乘客是否生还。你的模型需要基于乘客的特征,如乘客的性别、分类等。你也可以利用特征工程来创建新的特征。
测试集
测试集用来检查你的模型对于未知的数据能够有多好的效果。在测试集中,我们并没有提供乘客对应的生还情况。而是由你来预测乘客是否生还。利用你通过训练集训练出来的模型,对测试集中每位乘客的生还情况进行预测。
数据字典
| 变量 | 定义 | 值 |
|---|---|---|
| survival | 是否生还 | 0=No,1=Yes |
| pclass | 坐席类型 | 1=一等座, 2=二等座, 3=三等座 |
| sex | 性别 | |
| Age | 年龄 | |
| sibsp | 在船上的兄弟姐妹/配偶数量 | |
| parch | 在船上的父母/子女数量 | |
| ticket | 船票编号 | |
| fare | 票价 | |
| cabin | 船舱编号 | |
| embarked | 登船港口 | C=Cherbourg, Q=Queenstown, S=Southampton |
变量备注
pclass:表示社会经济地位
- 1:一等座上层
- 2:二等座中层
- 3:三层座底层
age:如果小于一岁,年龄是分数。如果年龄是估计的,其形式为 XX.5
sibsp/parch:数据集中家庭关系的定义
一些儿童仅仅由保姆陪同出行,因此他们的 parch = 0。
解决过程
整体框架
1、定义问题
在真正决定使用什么样的技术、算法之前,要明确我们要解决的问题是什么。而不是一股脑的就套用最新的技术、工具或算法。
2、收集数据
John Naisbitt 在他 1984 的书中写到“我们淹没在数据中,却在寻找知识”。所以,现在我们面临的是数据集已经以某种形式存在于某处。可能是开放的或者需要挖掘的,结构化或非结构化的、静态的或流式数据等等。你只需要知道如何去找到它们,然后将这些“脏数据”转化为“干净数据”。
3、准备数据
这一阶段经常被称为数据整理(data wrangling),其中一个必须的流程就是将“杂乱的”数据转换为“易于管理的”数据。数据整理包括以下几部分内容:
- 实现易于存储和处理的数据架构(data architecture)
- 开发质量与控制的数据治理(data governance)标准
- 数据抽取(data extraction)
- 以识别异常数据、缺失值以及离群值为目标的数据清理(data cleaning)
4、探索性分析
如果有过数据工作经验的人可能会知道垃圾输入(garbage-in)和垃圾输出(garbage-out)。因此应该使用描述性统计分析和图示统计分析在数据集中寻找潜在的问题、模式、分类、相关系数和对照等内容。另外,数据分类对于理解和选择合适的假设检验或数据模型是非常重要的。
5、模型数据
类似于描述性和推理性统计,数据模型可以总结并预测特征结果。通过数据集特征值以及预期结果分析,可以决定你的算法是否能够使用。需要注意的是算法并不是魔法棒或者银弹,你必须真正懂得如何去选择合适的工具解决对应的问题。
6、验证和实现模型
在基于一部分数据训练完成模型之后,需要检验模型。以确保没有对该部分子集数据过拟合。在这个阶段,我们确定模型是过拟合、泛化还是欠拟合。
7、优化
接下来就是不断的优化,让你的模型变得更好、更快、更强。
STEP 1. 定义问题
在这个项目中,问题的定义非常明确,并且已经在项目介绍中明确的给出了,开发一个算法用于预测泰坦尼克事故中乘客的生还情况。
在1912年4月15日发生的泰坦尼克沉船事件中,2224名乘客和船员中,有1502人丧生。在这次海难中导致如此多人员丧生的一个重要原因是没有足够的救生船。不过其中一些乘客的存活率要比其他乘客的存活率大,比如妇女/儿童和上层乘客。
在这个挑战中,我们期望你分析一下什么样的座次有利于提高存活率。并且,我们要求你应用机器学习工具来预测哪些用户在此次海难中存活下来。
STEP 2. 收集数据
在这个项目中,数据已经给定,直接下载即可。
STEP 3. 准备数据
TODO 一些描述
STEP 3.1. 准备环境(需要调整,不要一下子导入全部类库)
本项目代码基于 Python 3.x 编写。在正式编写代码之前,首先需要导入一些必要的依赖类库。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#load packages
import sys #access to system parameters https://docs.python.org/3/library/sys.html
print("Python version: {}". format(sys.version))
import pandas as pd #collection of functions for data processing and analysis modeled after R dataframes with SQL like features
print("pandas version: {}". format(pd.__version__))
import matplotlib #collection of functions for scientific and publication-ready visualization
print("matplotlib version: {}". format(matplotlib.__version__))
import numpy as np #foundational package for scientific computing
print("NumPy version: {}". format(np.__version__))
import scipy as sp #collection of functions for scientific computing and advance mathematics
print("SciPy version: {}". format(sp.__version__))
import sklearn #collection of machine learning algorithms
print("scikit-learn version: {}". format(sklearn.__version__))
#misc libraries
import random
import time
如果这些类库没有安装的话,需要先安装,除了 Numpy 其他都可以参照以下命令安装:1
pip install scikit-learn
Numpy安装最好到网站 Python Extension Packages 上下载安装。要先安装 Numpy 再安装其他类库。pip install scikit-learn
STEP 3.2. 基本分析
接下来要正式开始接触数据了。首先我们需要对数据集有一些基本的了解。比如说数据集看起来是什么样子的,稍微描述一下。其中有哪些特征? 每个特征大概起到什么样的作用?特征之间的依赖关系?
- Survived,是输出变量。1表示生还,0表示丧生。这个变量的所有值都需要我们进行预测。而除了这个变量以外的所有变量都可能是潜在的能够影响预测值的变量。需要注意的是,并不是说用于预测的变量越多,训练的模型就越好,而是正确的变量才对模型有益。
- PassengerId 和 Ticket,这两个变量是随机生成的唯一值,因此这两个值对结果变量不会有影响,因此在后续分析时,可以排除这两个变量。
- Pclass,是一个有序序列,用于表示社会经济地位,1表示上层人士;2表示中层;3表示底层。
- Name,是一个名词类型。可以利用特征工程从中获取性别,利用姓氏可以获得家庭成员数量,以及从称呼中可以分析出经济地位,比如XXX医生。不过这些变量目前已经明确的知道了,因此只需要通过称呼了解这个乘客是不是医生等内容。
- Sex 和 Embarked,也是名词变量。在后续的计算中会被转换成数值参与计算。
- Age 和 Fare,是连续型数值。
- Sibsp 和 Parch,分别表示在船上的兄弟姐妹、配偶以及父母、子女的数量。这两个都是离散型的整数值。这两个值可以用于特征工程,来创建一个家庭成员数量的变量。
- Cabin,是一个名词变量,可以用于特征工程中发现当事故发生时,其位于船上的位置,以及距离甲板的距离。然而,这一列很多都是空值,因此也不能用于分析。
我们导入数据,然后使用 sample() 方法来快速的观察一下数据。
1 | data_raw = pd.read_csv('./input/train.csv') # 读取训练集 |
打印结果:
| df_index | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 660 | 661 | 1 | 1 | Frauenthal, Dr. Henry William | male | 50.0 | 2 | 0 | PC 17611 | 133.6500 | NaN | S |
| 382 | 383 | 0 | 3 | Tikkanen, Mr. Juho | male | 32 | 0 | 0 | STON/O 2. 3101293 | 7.925 | S | |
| 64 | 65 | 0 | 1 | Stewart, Mr. Albert A | male | 0 | 0 | PC 17605 | 27.7208 | C | ||
| 697 | 698 | 1 | 3 | Mullens, Miss. Katherine “Katie” | female | 0 | 0 | 35852 | 7.7333 | Q | ||
| 345 | 346 | 1 | 2 | Brown, Miss. Amelia “Mildred” | female | 24 | 0 | 0 | 248733 | 13 | F33 | S |
| 525 | 526 | 0 | 3 | Farrell, Mr. James | male | 40.5 | 0 | 0 | 367232 | 7.75 | Q | |
| 883 | 884 | 0 | 2 | Banfield, Mr. Frederick James | male | 28 | 0 | 0 | C.A./SOTON 34068 | 10.5 | S | |
| 487 | 488 | 0 | 1 | Kent, Mr. Edward Austin | male | 58 | 0 | 0 | 11771 | 29.7 | B37 | C |
| 553 | 554 | 1 | 3 | Leeni, Mr. Fahim (Philip Zenni) | male | 22 | 0 | 0 | 2620 | 7.225 | C | |
| 241 | 242 | 1 | 3 | Murphy, Miss. Katherine “Kate” | female | 1 | 0 | 367230 | 15.5 | Q |
STEP 3.3. 数据清理
在本节中,我们将会对数据进行清理,包括修正异常值;补全缺失值;通过分析创建新的特征;格式转换,将数据转换为便于计算和展示的格式。
1、修正
检查数据,看看是否有任何看起来异常的输入。我们发现在年龄和票价两列,似乎存在异常值。不过客观的来说,这些值也是合理的,因此我们等到进行探索性数据分析时,再决定是否要剔除这两列。不过,如果这些值是一些客观上讲完全不可能的值,比如说年龄=800,那么就可能需要立马处理这个值。不过在处理这些值的时候,需要非常谨慎,因为我们需要获得一个尽可能精确的众数。
2、补全
在年龄、船舱编号、和登船港口等字段都有空值或缺失值。空值对于某些算法来说是不友好的,因为它们无法处理空值。因为需要利用几种不同的算法计算不同的模型,然后进行比较,因此要在真正开始模型训练之前,处理这些空值。有两种方法处理缺失值:1)删除缺失值对应的这条记录;2)利用一些可靠的输入填充缺失值。
一般而言,不建议删除缺失值记录,特别是当缺失值占比重很大时。一种比较基础的方法是利用平均数、中位数或者平均数加上一个随机标准偏差来填充缺失值。
稍微高级一些的方法是基于特定条件的缺失值填充。比如基于座位的等次划分不同的年龄平均数进行年龄缺失值的填充。基于票价和社会经济地位来进行登船港口的填充。当然还有一些更复杂的方法,不过在此之前,应该首先建立基线模型,然后将复杂方法填充的数据训练的模型与其进行比较,以决定是否使用复杂的填充方法。
在这个数据集中,我们使用中位数来填充年龄的缺失值,而船舱这个特征会被丢弃。我们会使用一个模型来填充登船港口的缺失值,通过迭代来决定填充的值是否对模型的精度有所改善。
3、创建
所谓特征工程,就是利用已有的特征来创建新的特征,并且判断这个新的特征对于模型的构建是否有促进作用。在这个数据集中,我们利用特征工程来创建一个“头衔”特征,判断角色对于生还情况是否有影响。
4、转换
最后,我们要处理格式化的问题。虽然没有诸如日期、货币等字段需要格式化,但是我们有一些数据类型需要转换。比如我们的分类数据是以分类的名称表示的,无法进行数学运算。我们需要将这个数据集中的一些数据转换为可以用于数据运算的变量类型。
STEP 3.3.1. 观察数据
查看训练集中数据的空值情况:1
print('Train columns with null values:\n', data_raw.isnull().sum())
结果如下。可以看到其中的年龄和船舱分别都有较多空值,登船港口存在两个空值,其余字段基本没有空值。1
2
3
4
5
6
7
8
9
10
11
12
13Train columns with null values:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
以同样的方法查看测试集中的数据:1
print('Train columns with null values:\n', data_val.isnull().sum())
结果如下。同样是年龄和船舱两个字段存在较多空值。1
2
3
4
5
6
7
8
9
10
11
12Test/Validation columns with null values:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
查看训练集整体数据情况。从这个统计数据中我们可以看到一些数据的分布情况,比如最大值、最小值、中位数、数据出现的频度等数据。1
print(data_raw.describe(include = 'all'))
| Type | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 891 | 891 | 714.000000 | 891.000000 | 891.000000 | 891 | 891.000000 | 204 | 889 |
| unique | NaN | NaN | NaN | 891 | 2 | NaN | NaN | NaN | 681 | NaN | 147 | 3 |
| top | NaN | NaN | NaN | Hirvonen, Miss. Hildur E | male | NaN | NaN | NaN | CA. 2343 | NaN | G6 | S |
| freq | NaN | NaN | NaN | 1 | 577 | NaN | NaN | NaN | 7 | NaN | 4 | 644 |
| mean | 446.000000 | 0.383838 | 2.308642 | NaN | NaN | 29.699118 | 0.523008 | 0.381594 | NaN | 32.204208 | NaN | NaN |
| std | 257.353842 | 0.486592 | 0.836071 | NaN | NaN | 14.526497 | 1.102743 | 0.806057 | NaN | 49.693429 | NaN | NaN |
| min | 1.000000 | 0.000000 | 1.000000 | NaN | NaN | 0.420000 | 0.000000 | 0.000000 | NaN | 0.000000 | NaN | NaN |
| 25% | 223.500000 | 0.000000 | 2.000000 | NaN | NaN | 20.125000 | 0.000000 | 0.000000 | NaN | 7.910400 | NaN | NaN |
| 50% | 446.000000 | 0.000000 | 3.000000 | NaN | NaN | 28.000000 | 0.000000 | 0.000000 | NaN | 14.454200 | NaN | NaN |
| 75% | 668.500000 | 1.000000 | 3.000000 | NaN | NaN | 38.000000 | 1.000000 | 0.000000 | NaN | 31.000000 | NaN | NaN |
| max | 891.000000 | 1.000000 | 3.000000 | NaN | NaN | 80.000000 | 8.000000 | 6.000000 | NaN | 512.329200 | NaN | NaN |
STEP 3.3.2. 修正
将训练集拷贝一个副本,然将副本与测试集合并形成一个新的集合。1
2data_raw2 = data_raw.copy(deep = True)
data_cleaner = [data_raw2, data_val]
后续的操作基于这个拷贝的副本进行。
在这个数据集中,通过上面的观察,并没有发现明显不符合客观事实的值,因此不需要进行处理。不过其中存在一个无用的列,包括乘客ID,船舱、船票编号,需要将这几个列删除。1
2drop_column = ['PassengerId','Cabin', 'Ticket']
data_raw2.drop(drop_column, axis=1, inplace = True)
观察一下删除后的空值情况:1
2
3
4
5print('Train columns with null values:\n', data_raw2.isnull().sum())
print("-" * 25)
print('Test/Validation columns with null values:\n', data_val.isnull().sum())
print("-" * 25)
结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27-------------------------
Train columns with null values:
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Embarked 2
dtype: int64
-------------------------
Test/Validation columns with null values:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
-------------------------
STEP 3.3.3. 补全
这里的 data_cleaner 只是一个引用,对其修改,会直接反映到 data_raw2 和 data_val 上。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15for dataset in data_cleaner:
# 使用中位数填充所有空值
dataset['Age'].fillna(dataset['Age'].median(), inplace = True)
# 使用众数填充登船港口
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0], inplace = True)
# 使用中位数填充票价
dataset['Fare'].fillna(dataset['Fare'].median(), inplace = True)
print('Train columns with null values:\n', data_raw2.isnull().sum())
print("-" * 25)
print('Test/Validation columns with null values:\n', data_val.isnull().sum())
print("-" * 25)
同样的将处理后的结果打印出来看看:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26Train columns with null values:
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
-------------------------
Test/Validation columns with null values:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64
-------------------------
STEP 3.3.4. 创建
利用特征工程将训练集和测试集中的数据创建新的特征。这里我们根据现有的 特征分别创建几个新的特征。
1、根据兄弟姐妹、配偶、父母和子女数量的两个字段来创建一个表示家庭成员数量的字段。利用家庭成员数量可以得到一个新的字段表示是否是孤身一人。
2、观察姓名一列,可以看到其中有关于头衔之类的信息,从中可以看到是先生、女士、硕士、博士等等信息。
3、将船票费用和年龄划分为几个不同的区间。
1 | for dataset in data_cleaner: |
查看增加了几个特征之后的数据:
| df_index | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | FamilySize | IsAlone | Title | FareBin | AgeBin |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 205 | 0 | 3 | Strom, Miss. Telma Matilda | female | 2.0 | 0 | 1 | 10.4625 | S | 2 | 0 | Miss | (7.91, 14.454] | (-0.08, 16.0] |
| 879 | 1 | 1 | Potter, Mrs. Thomas Jr (Lily Alexenia Wilson) | female | 56.0 | 0 | 1 | 83.1583 | C | 2 | 0 | Mrs | (31.0, 512.329] | (48.0, 64.0] |
| 329 | 1 | 1 | Hippach, Miss. Jean Gertrude | female | 16.0 | 0 | 1 | 57.9792 | C | 2 | 0 | Miss | (31.0, 512.329] | (-0.08, 16.0] |
| 136 | 1 | 1 | Newsom, Miss. Helen Monypeny | female | 19.0 | 0 | 2 | 26.2833 | S | 3 | 0 | Miss | (14.454, 31.0] | (16.0, 32.0] |
| 57 | 0 | 3 | Novel, Mr. Mansouer | male | 28.5 | 0 | 0 | 7.2292 | C | 1 | 1 | Mr | (-0.001, 7.91] | (16.0, 32.0] |
| 848 | 0 | 2 | Harper, Rev. John | male | 28.0 | 0 | 1 | 33.0 | S | 2 | 0 | Rev | (31.0, 512.329] | (16.0, 32.0] |
| 151 | 1 | 1 | Pears, Mrs. Thomas (Edith Wearne) | female | 22.0 | 1 | 0 | 66.6 | S | 2 | 0 | Mrs | (31.0, 512.329] | (16.0, 32.0] |
| 659 | 0 | 1 | Newell, Mr. Arthur Webster | male | 58.0 | 0 | 2 | 113.275 | C | 3 | 0 | Mr | (31.0, 512.329] | (48.0, 64.0] |
| 228 | 0 | 2 | Fahlstrom, Mr. Arne Jonas | male | 18.0 | 0 | 0 | 13.0 | S | 1 | 1 | Mr | (7.91, 14.454] | (16.0, 32.0] |
| 371 | 0 | 3 | Wiklund, Mr. Jakob Alfred | male | 18.0 | 1 | 0 | 6.4958 | S | 2 | 0 | Mr | (-0.001, 7.91] | (16.0, 32.0] |
对于头衔这一列,由于是拆分字符串,因此对于结果需要着重检查一下,打印这一列的统计信息:1
print(data_raw2['Title'].value_counts())
观察结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Mlle 2
Col 2
Major 2
the Countess 1
Jonkheer 1
Capt 1
Mme 1
Ms 1
Sir 1
Lady 1
Don 1
我们发现,拆分出来的头衔有很多种,不过其中占比比较高的就是前面四个,后面的一些数量都太少,因此我们打算将后面的一些都合并成一个。1
2
3
4stat_min = 10
title_names = (data_raw2['Title'].value_counts() < stat_min)
data_raw2['Title'] = data_raw2['Title'].apply(lambda x: 'Misc' if title_names.loc[x] == True else x)
print(data_raw2['Title'].value_counts())
再次观察处理后的结果:1
2
3
4
5Mr 517
Miss 182
Mrs 125
Master 40
Misc 27
发现头衔这一列已经全部处理为这几类,对于数量比较少的,都归入到 Misc 中。
STEP 3.3.5. 转换
接下来我们需要将分类数据转换为离散特征编码用于数学分析。另外,在本环节中,我们还会定义用于训练模型的 x (输入)和 y (输出)变量。
首先利用标签编码将几个离散型的列转换为标签。1
2
3
4
5
6
7label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
| df_index | Other Columns | Sex_Code | Embarked_Code | Title_Code | AgeBin_Code | FareBin_Code |
|---|---|---|---|---|---|---|
| 312 | … | 0 | 2 | 4 | 1 | 2 |
| 394 | … | 0 | 2 | 4 | 1 | 2 |
| 75 | … | 1 | 2 | 3 | 1 | 0 |
| 794 | … | 1 | 2 | 3 | 1 | 0 |
| 348 | … | 1 | 2 | 0 | 0 | 2 |
| 330 | … | 0 | 1 | 2 | 1 | 2 |
| 517 | … | 1 | 1 | 3 | 1 | 2 |
| 203 | … | 1 | 0 | 3 | 2 | 0 |
| 573 | … | 0 | 1 | 2 | 1 | 0 |
| 176 | … | 1 | 2 | 0 | 1 | 2 |
将其中的一些离散型变量转为独热编码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 定义输出变量 y
Target = ['Survived']
# 定义输入变量 x
data_raw2_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone']
data_raw2_x_calc = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code','SibSp', 'Parch', 'Age', 'Fare']
data_raw2_xy = Target + data_raw2_x
print('Original X Y: ', data_raw2_xy, '\n')
# 定义离散输入变量 x
data_raw2_x_bin = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
data_raw2_xy_bin = Target + data_raw2_x_bin
print('Bin X Y: ', data_raw2_xy_bin, '\n')
# 将离散型变量转为独热编码
data_raw2_dummy = pd.get_dummies(data_raw2[data_raw2_x])
data_raw2_x_dummy = data_raw2_dummy.columns.tolist()
data_raw2_xy_dummy = Target + data_raw2_x_dummy
print('Dummy X Y: ', data_raw2_xy_dummy, '\n')
print(data_raw2_dummy.sample(10))
输出结果:
| df_index | Pclass | SibSp | Parch | Age | Fare | FamilySize | IsAlone | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | Title_Master | Title_Misc | Title_Miss | Title_Mr | Title_Mrs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 154 | 3 | 0 | 0 | 28.0 | 7.3125 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 317 | 2 | 0 | 0 | 54.0 | 14.0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 216 | 3 | 0 | 0 | 27.0 | 7.925 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 177 | 1 | 0 | 0 | 50.0 | 28.7125 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 514 | 3 | 0 | 0 | 24.0 | 7.4958 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 552 | 3 | 0 | 0 | 28.0 | 7.8292 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 785 | 3 | 0 | 0 | 25.0 | 7.25 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 324 | 3 | 8 | 2 | 28.0 | 69.55 | 11 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 135 | 2 | 0 | 0 | 23.0 | 15.0458 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 79 | 3 | 0 | 0 | 30.0 | 12.475 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
STEP 3.3.6. 拆分训练集
前面提到项目给定了两个数据集,一个是训练集,一个是测试集。但是在真正开始进行模型训练时,我们需要将这个训练集拆分为两部分,使用其中一部分进行模型训练,另一部分进行验证,以防止过拟合。
1 | train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data_raw2[data_raw2_x_calc], data_raw2[Target], random_state = 0) |
STEP 4. 探索性数据分析
现在已经完成了数据清理,我们需要利用统计和图示工具来找出分类特征,已经判断其与输出或其他特征之间的相关性。
STEP 4.1. 单变量相关性分析
STEP 4.1.1. 基于数值统计的分析
对离散型特征分别进行分组统计,分析不同类型的值与生还情况之间的关系。
1 | for x in data_raw2_x: |
生还情况的关系*
生还者程:将数据按照性别分为两组,分别求每组 Survived 的平均值,由于生还者标志为 1,丧生为 0,则该平均数正好可以表示每个分组中生还者占的百分比。1
2
3
4Survival Correlation by: Sex
Sex Survived
0 female 0.742038
1 male 0.188908
**根据该统计结果,发现女性中,生还者占 74% 左右,而男性中的生还者占比只有 19% 左右。
座位等级与生还情况与座次关系:
一等座中有 62% 的生还者;二等座则有 47% 的生还者;三等座只有 24% 的生还者。因此坐席等级越高,其存活可能性就相对越高。1
2
3
4
5Survival Correlation by: Pclass
Pclass Survived
0 1 0.629630
1 2 0.472826
2 3 0.242363
生还率与登船港口关系:
从 Cherbourg 登船的乘客生还率要显著高于其他两个港口登船的乘客。1
2
3
4
5Survival Correlation by: Embarked
Embarked Survived
0 C 0.553571
1 Q 0.389610
2 S 0.339009
生还率与头衔之间的关系:1
2
3
4
5
6
7Survival Correlation by: Title
Title Survived
0 Master 0.575000
1 Misc 0.444444
2 Miss 0.697802
3 Mr 0.156673
4 Mrs 0.792000
生还率与兄弟姐妹和配偶数量关系:
我们发现在船上拥有 1 到 2 名兄弟姐妹或配偶的人员生存率比较高,达到 53% 和 46%,其余都很低。1
2
3
4
5
6
7
8
9Survival Correlation by: SibSp
SibSp Survived
0 0 0.345395
1 1 0.535885
2 2 0.464286
3 3 0.250000
4 4 0.166667
5 5 0.000000
6 8 0.000000
生还率与父母子女数量关系:
通船上父母与子女的数量与生存情况关系,有1-3人的生存率最高,在 50~60%之间。1
2
3
4
5
6
7
8
9Survival Correlation by: Parch
Parch Survived
0 0 0.343658
1 1 0.550847
2 2 0.500000
3 3 0.600000
4 4 0.000000
5 5 0.200000
6 6 0.000000
生还率与家庭成员数量关系:
总的家庭成员在 4 人左右的存活率较高,可能是什么原因?或许可以分析一下这些存货下来的人员对应的家庭成员,特别是男性家庭成员的存货情况。1
2
3
4
5
6
7
8
9
10
11Survival Correlation by: FamilySize
FamilySize Survived
0 1 0.303538
1 2 0.552795
2 3 0.578431
3 4 0.724138
4 5 0.200000
5 6 0.136364
6 7 0.333333
7 8 0.000000
8 11 0.000000
生还率与是否独身一人的关系:1
2
3
4Survival Correlation by: IsAlone
IsAlone Survived
0 0 0.505650
1 1 0.303538
STEP 4.1.2. 基于箱线图和直方图的分析
票价分布情况与生还情况关系1
2
3
4
5
6
7
8
9
10
11
12plt.figure(figsize=[16,12])
plt.subplot(121)
plt.boxplot(x=data_raw2['Fare'], showmeans = True, meanline = True)
plt.title('Fare Boxplot')
plt.ylabel('Fare ($)')
plt.subplot()
pla_e'], ')
plt.label(')
plt.show()
结果: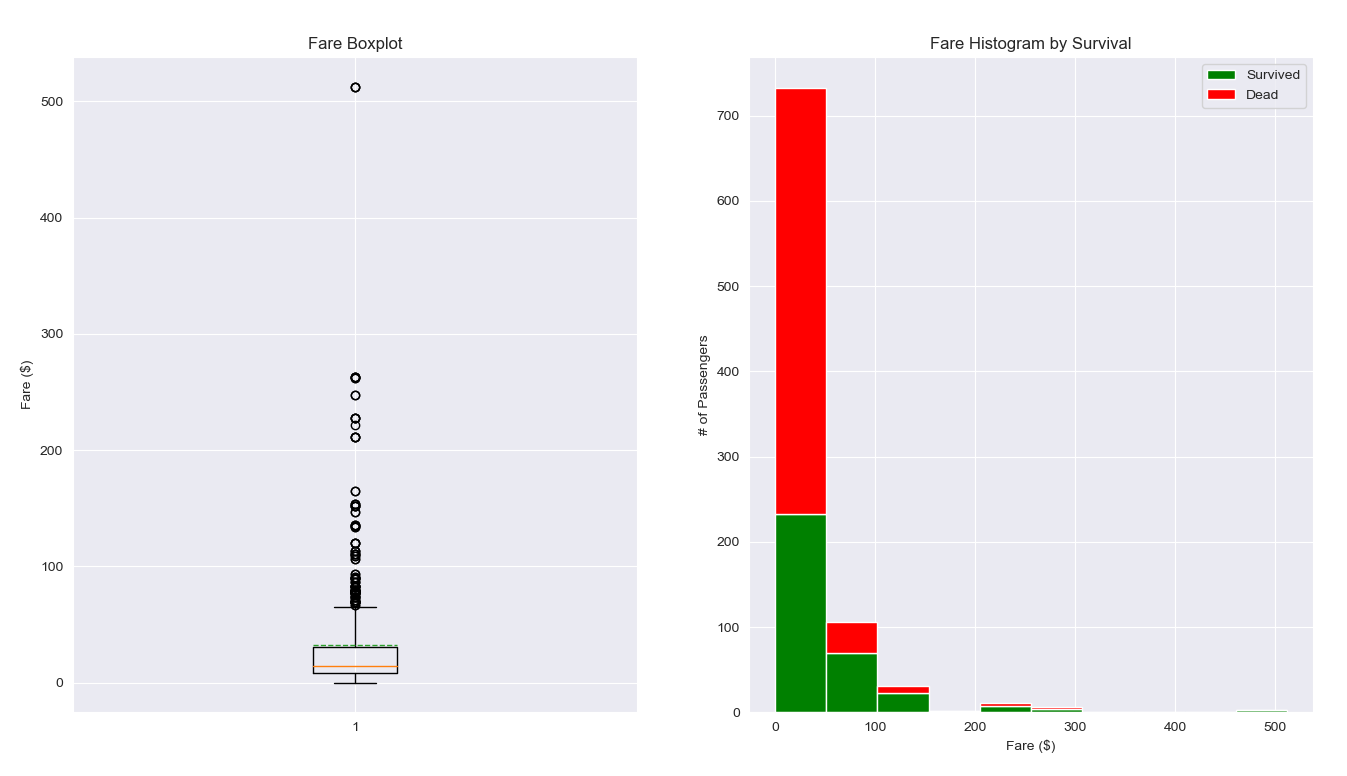
观察票价分布的箱线图,可以看出来票价的主要分布区间大概在 5 ~ 40 之间,上限在 80 左右,票价中存在部分离群点,应该不是异常值,是属于比较高档的票价。
观察票价与生还情况直方图,可以看出来在 0 ~ 50 票价的乘客存活率相对较低,大概只有 30% 左右,而票价越高,其存活率基本上是不断上升的。
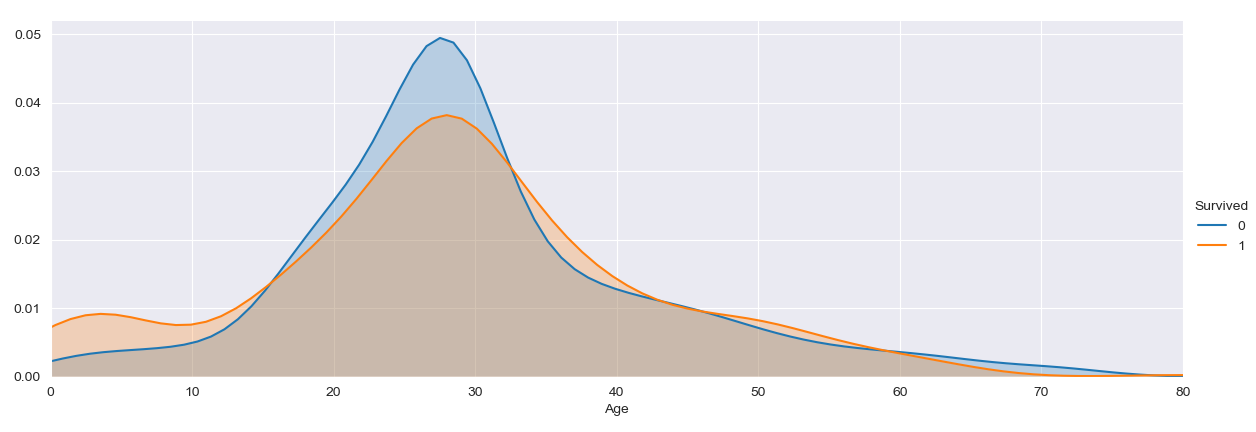
年龄分布情况与生还情况关系
1 | plt.figure(figsize=[16,12]) |
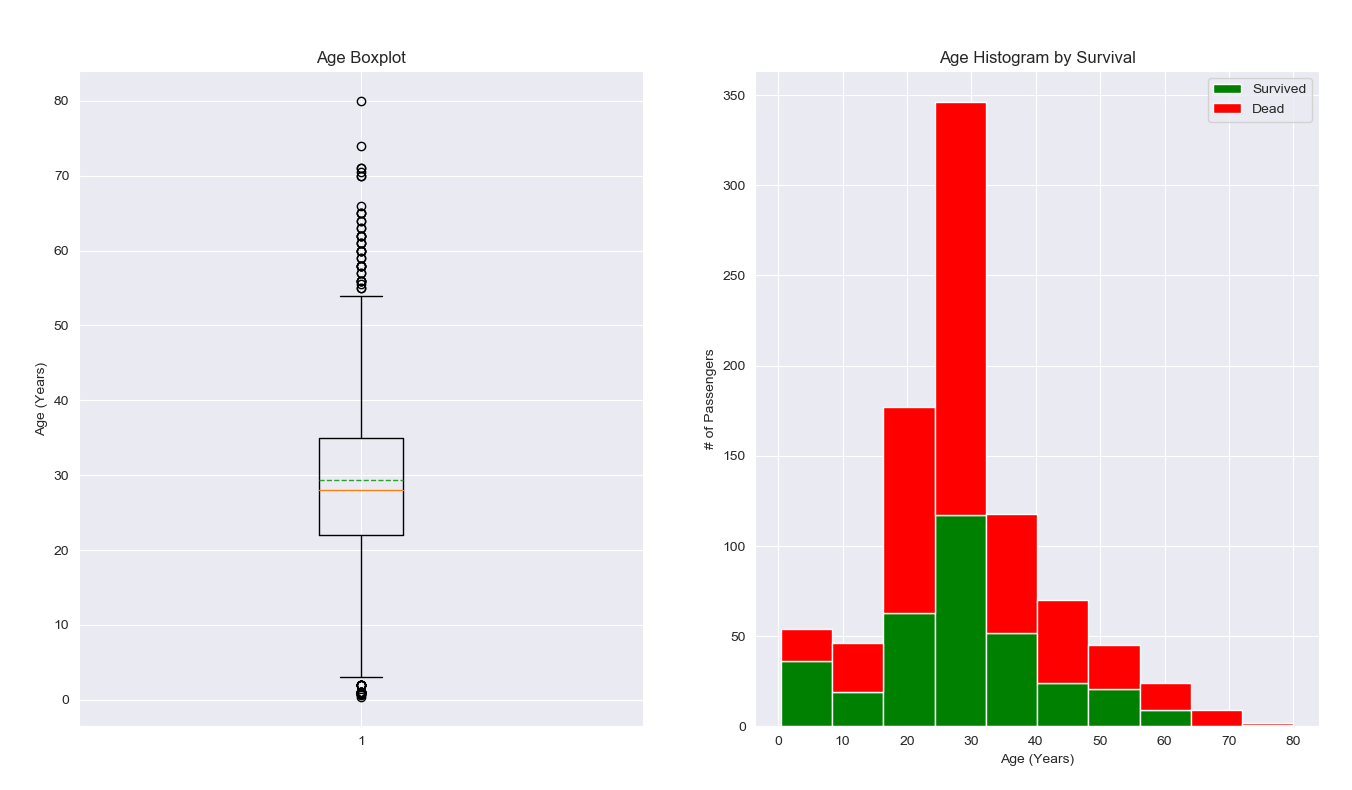
观察年龄分布的箱线图,可以看出来年龄的主要分布区间大概在 20 ~ 35 之间,大部分应该属于青壮年。存在部分离群点,可能是年龄较大的老年人和幼儿。
观察年龄与生还情况直方图,可以看出来在 30 岁区间的乘客存活率相对较低,低于30% ,其中很多人可能是牺牲了自己把求生的机会让给别人了。其余年龄分布的存活率也都相对不高,只有幼儿,青少年和50岁以上的老人存活率较高。
家庭成员数量分布情况与生还情况关系1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17plt.figure(figsize=[16,12])
plt.subplot(235121)
plt.hist(x = [data_raw2[data_raw2['Survived']==1]['Age'], data_raw2[data_raw2['Survived']==0]['Agboxplot(data_raw2['FamilySize']],
stacked=True, color = ['g','r'],label = ['Survived','Dead'])
plt.title('Age Histogram by Survivalshowmeans = True, meanline = True)
plt.title('Family Size Boxplot')
plt.xylabel('Age (Years)')
plt.ylabel('# of Passengers')
plt.legend(Family Size (#)')
plt.subplot(236122)
plt.hist(x = [data_raw2[data_raw2['Survived']==1]['FamilySize'], data_raw2[data_raw2['Survived']==0]['FamilySize']],
stacked=True, color = ['g','r'],label = ['Survived','Dead'])
plt.title('Family Size Histogram by Survival')
plt.xlabel('Family Size (#)')
plt.ylabel('# of Passengers')
plt.legend()
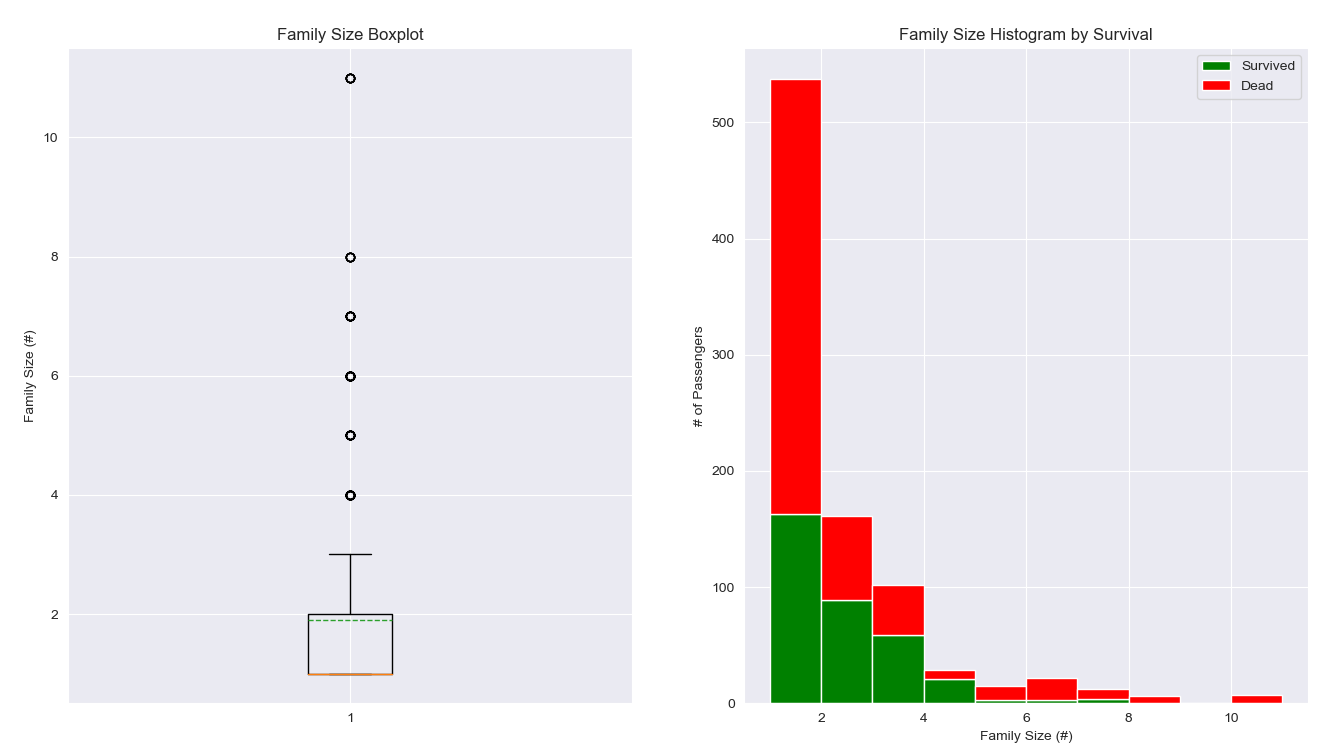
观察家庭成员数量分布的箱线图,可以看出来家庭成员数量的主要分布区间大概在 1 ~ 2 之间。
观察家庭成员数量与生还情况直方图,可以看出来在 2 ~ 5 区间的乘客存活率相对较高,高于50% ,可能这个数量的家庭成员相对比较集中,并且能够相互帮助求生。
STEP 4.1.3. 基于直方图的分析
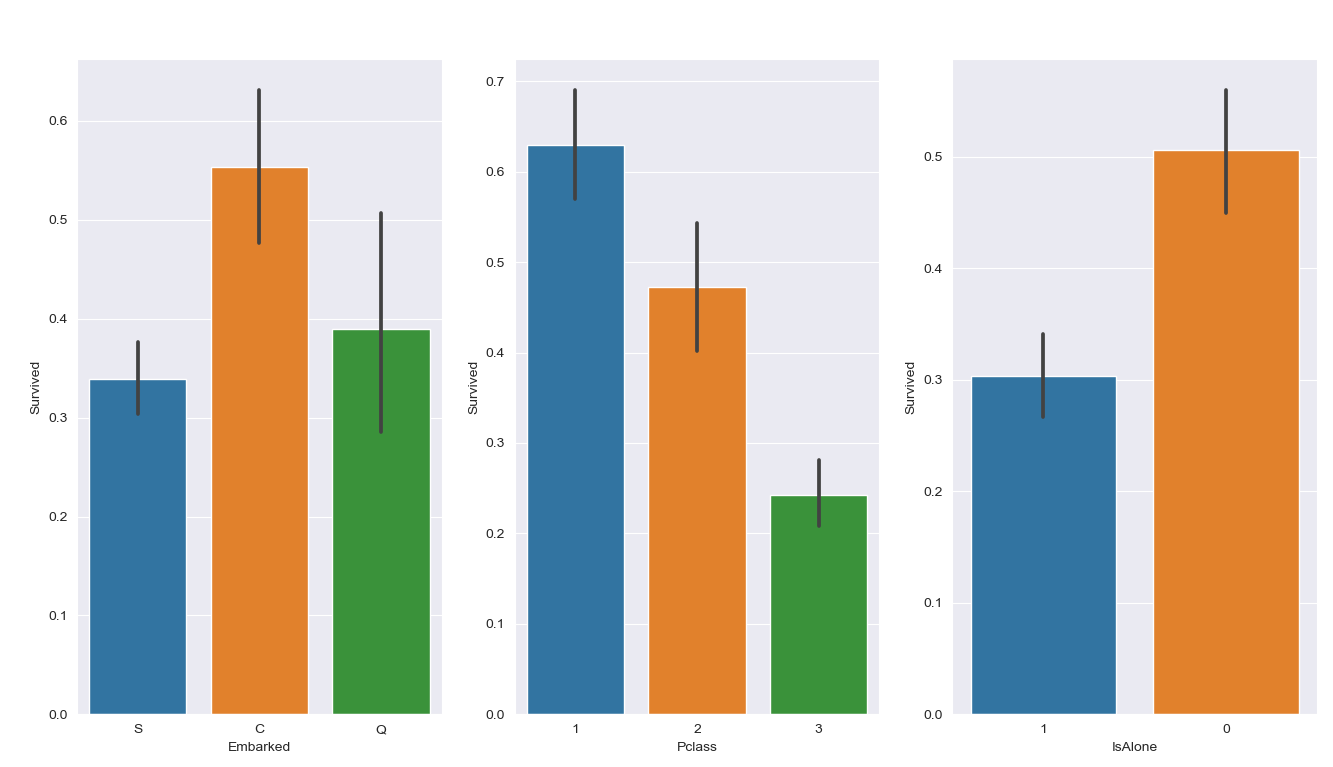
以图形化的方式展示一开始采用的数学统计的分析结果,按照分组展示每个特征不同值对应的生还率。
1 | fig, saxis = plt.subplots(, 3,figsize=(16,12)) |
STEP 4.1.4. 基于折线图的分析
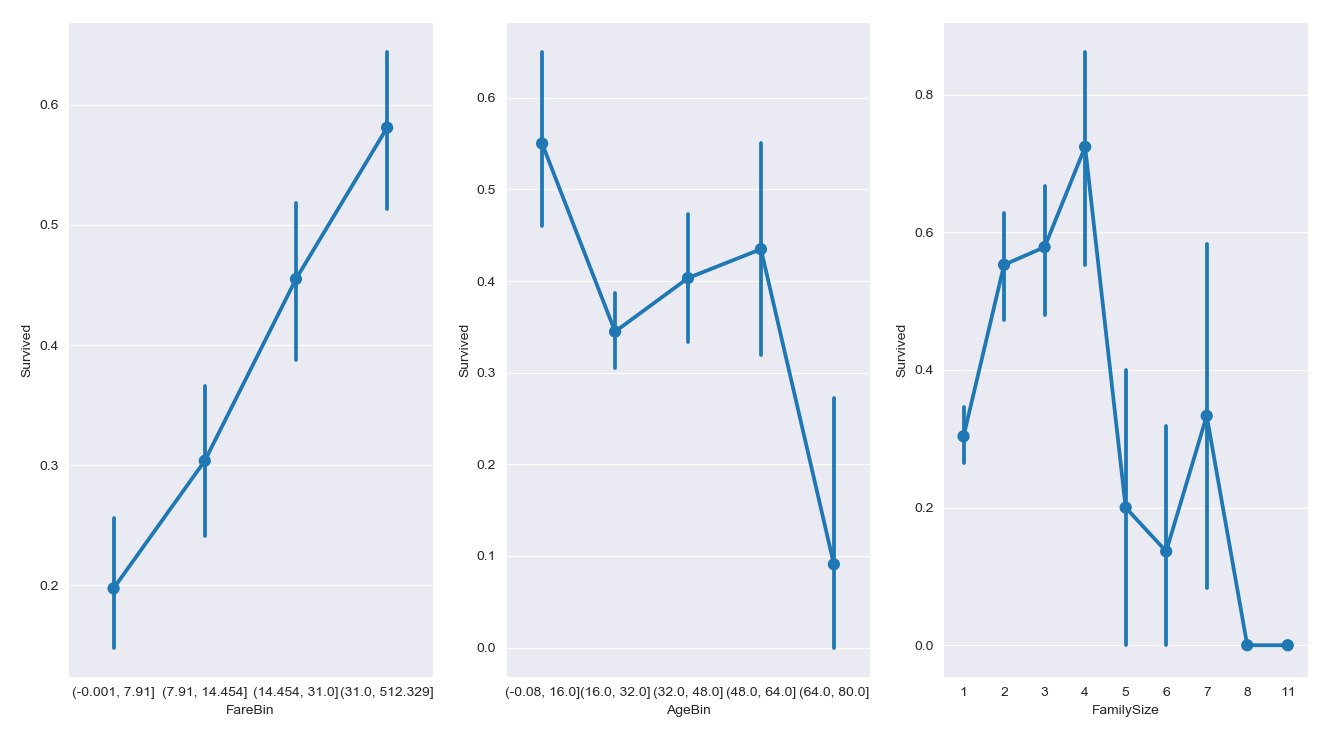
分析票价区间、年龄区间与家庭成员数量与生还率之间的关系,通过折线图比较直观的看出彼此之间的区别。
基本上票价越高的,存活率越高;而年龄主要是16所以下的青少年和 48 ~ 64 岁之间的老年存活率较高。1
2
3
4fig, saxis = plt.subplots(1, 3,figsize=(16,12))
sns.pointplot(x = 'FareBin', y = 'Survived', data=data_raw2, ax = saxis[0])
sns.pointplot(x = 'AgeBin', y = 'Survived', data=data_raw2, ax = saxis[1])
sns.pointplot(x = 'FamilySize', y = 'Survived', data=data_raw2, ax = saxis[2])
STEP 4.2. 双变量相关性分析
STEP 4.2.1. 座位等次与票价、年龄家庭规员数量与生还情况的关系
1 | fig, (axis1,axis2,axis3) = plt.subplots(1,3,figsize=(14,12)) |
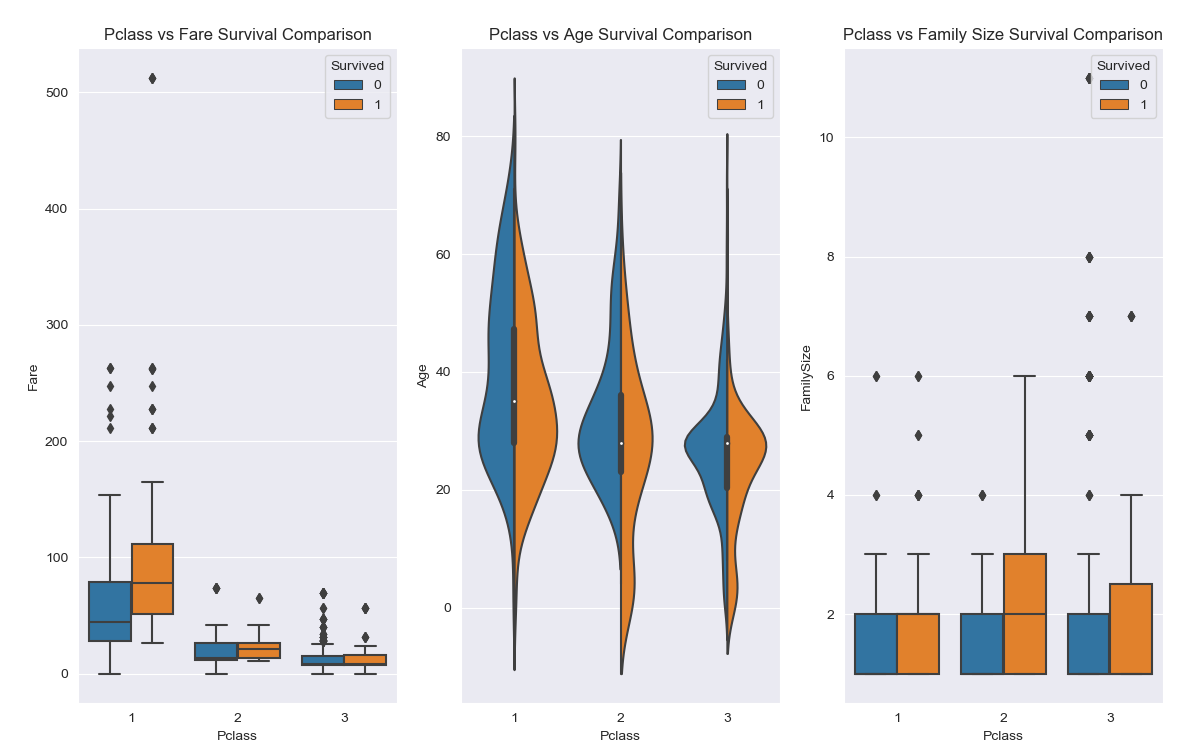
从图中我们可以发下以下一些内容:
- 一等座中票价较高的乘客存活率较高,而二等座和三等座中票价对存活率没有太大影响;
- 一等座中存活下来的基本上是年龄较大的,而二等座青少年存活率较高,三等座也是类似;
- 一等座中家庭成员数量基本在 2 人左右,存活率相仿,二等座和三等座家庭成员较多,存活率较高的基本都分布在 2 ~ 3 人左右;
STEP 4.2.2. 性别和登船港口、座位等次、是否独自一人与生还情况的关系
1 | fig, qaxis = plt.subplots(1,3,figsize=(14,12)) |
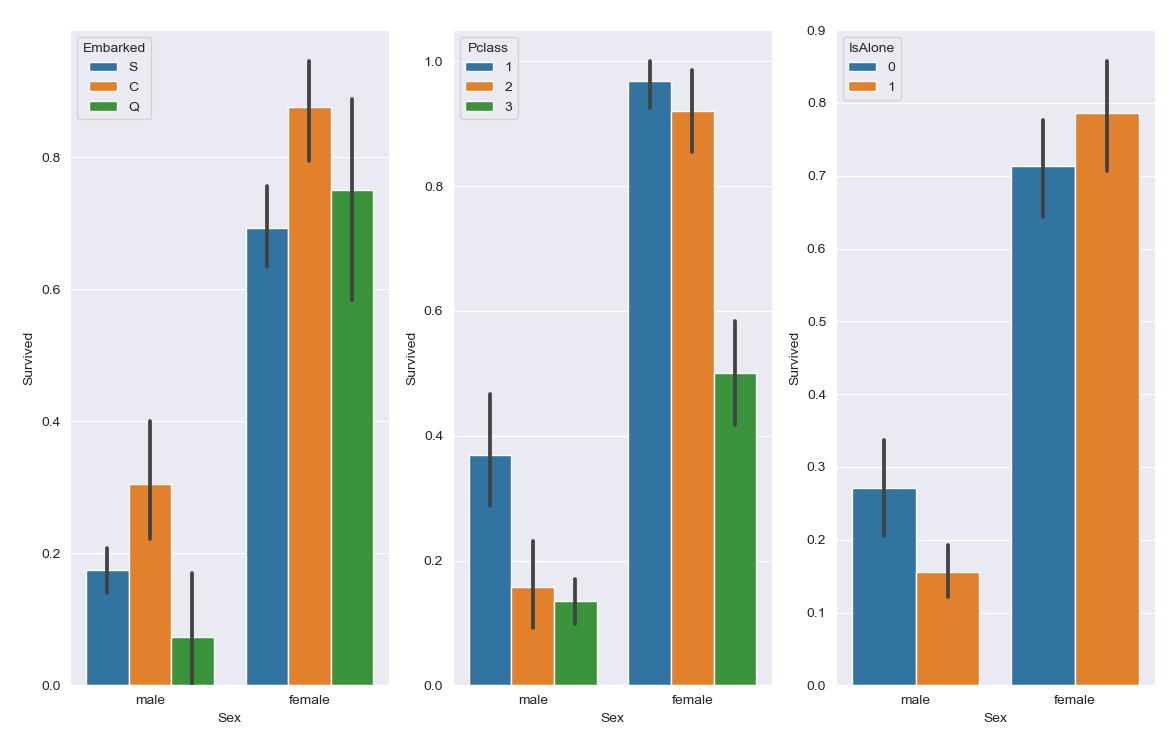
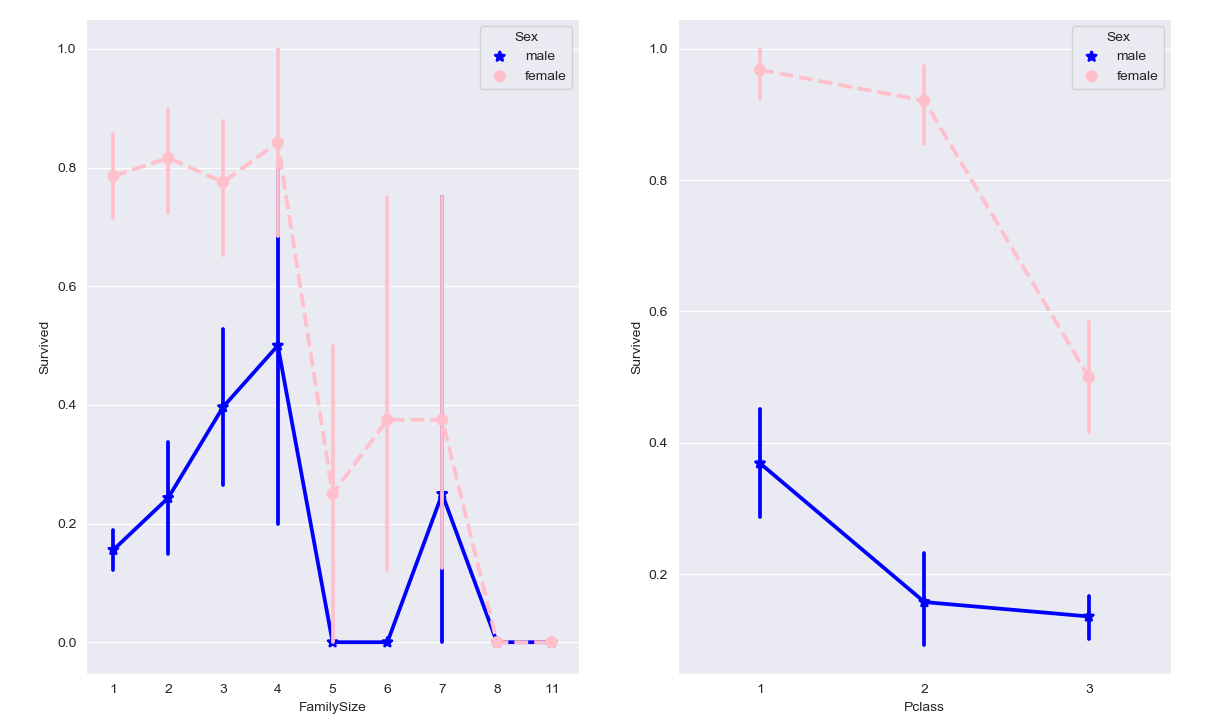
利用折线图:1
2
3
4
5
6
7
8
9
10
11fig, (maxis1, maxis2) = plt.subplots(1, 2,figsize=(14,12))
#how does family size factor with sex & survival compare
sns.pointplot(x="FamilySize", y="Survived", hue="Sex", data=data_raw2,
palette={"male": "blue", "female": "pink"},
markers=["*", "o"], linestyles=["-", "--"], ax = maxis1)
#how does class factor with sex & survival compare
sns.pointplot(x="Pclass", y="Survived", hue="Sex", data=data_raw2,
palette={"male": "blue", "female": "pink"},
markers=["*", "o"], linestyles=["-", "--"], ax = maxis2)
1 | a = sns.FacetGrid( data_raw2, hue = 'Survived', aspect=4 ) |
STEP 4.2.3. 相关热力图
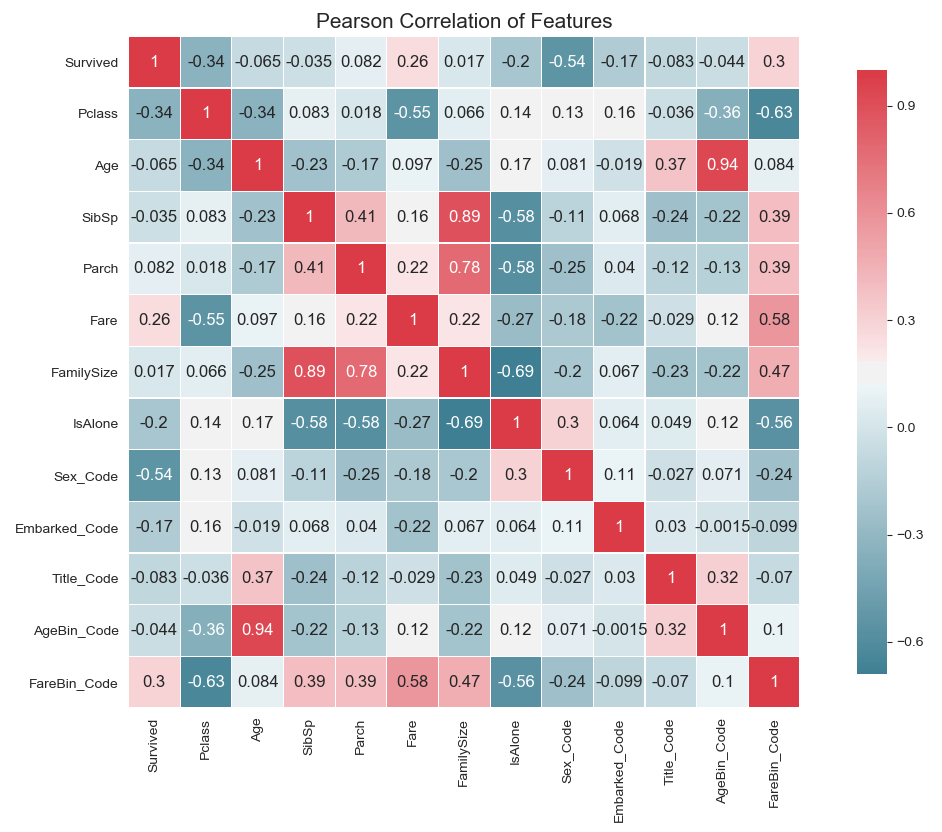
1 | def correlation_heatmap(df): |
STEP 5. 模型数据
接下来到了我们使用算法结合数据训练模型的阶段了。首先我们要面临的一个问题就是如何选择合适的算法。
STEP 5.1. 如何选择一个机器学习算法
一般来说在选择机器学习算法中有一个很著名的理论,No Free Lunch Theorem,没有免费的午餐定理。就是说没有一个算法能够适用于所有问题,因此针对不同的问题需要使用不同的算法处理。
下面使用一些主流算法分别训练模型,然后观察结果。
1 | MLA = [ |
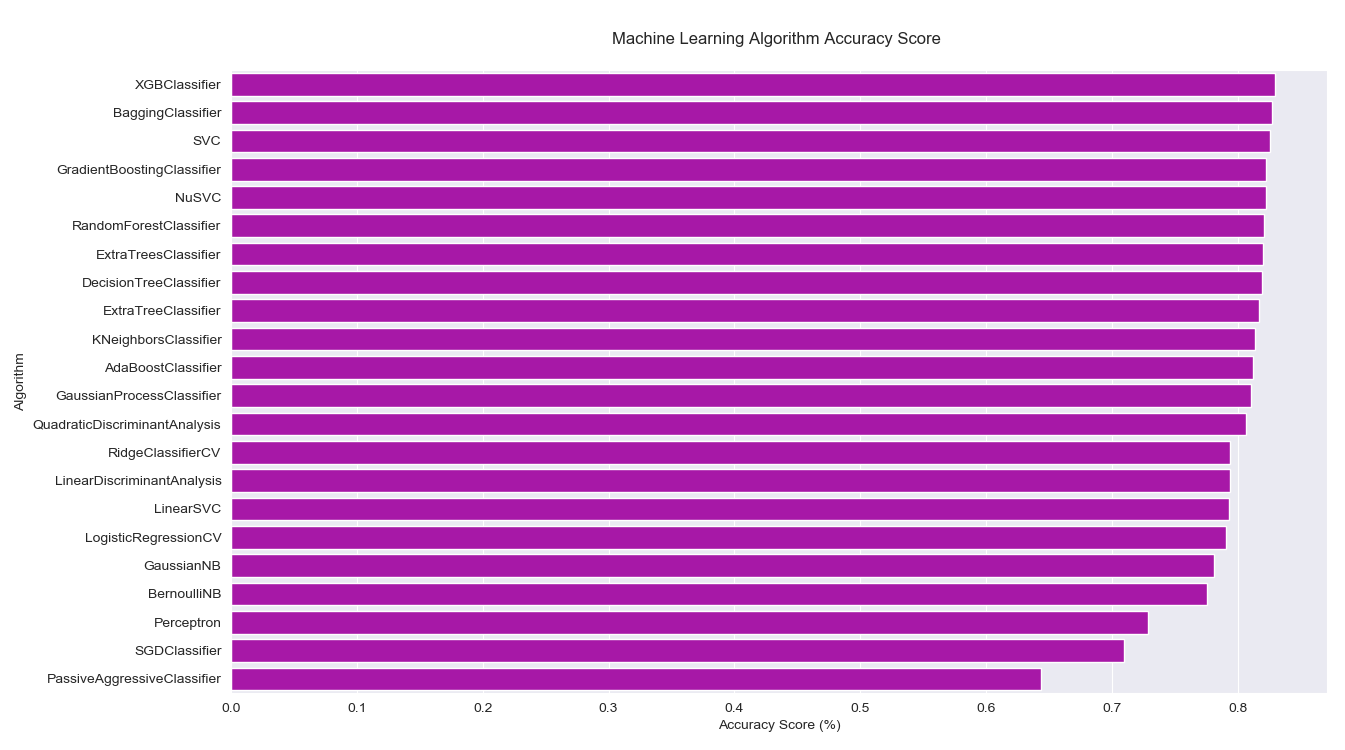
结果按照测试准确率从高到低排序:
| # | MLA Name | MLA Train Accuracy Mean | MLA Test Accuracy Mean | MLA Test Accuracy 3*STD | MLA Time |
|---|---|---|---|---|---|
| 21 | XGBClassifier | 0.856367041 | 0.829477612 | 0.052754649 | 0.039702296 |
| 14 | SVC | 0.837265918 | 0.826119403 | 0.045387616 | 0.041802382 |
| 2 | ExtraTreesClassifier | 0.895131086 | 0.823134328 | 0.070477953 | 0.019001102 |
| 3 | GradientBoostingClassifier | 0.866666667 | 0.822761194 | 0.04987314 | 0.076404333 |
| 15 | NuSVC | 0.83576779 | 0.822761194 | 0.049368083 | 0.053803039 |
| 17 | DecisionTreeClassifier | 0.895131086 | 0.820895522 | 0.05321581 | 0.003500175 |
| 4 | RandomForestClassifier | 0.8917603 | 0.820522388 | 0.077465598 | 0.021201277 |
| 1 | BaggingClassifier | 0.89082397 | 0.817910448 | 0.07621811 | 0.016200852 |
| 13 | KNeighborsClassifier | 0.850374532 | 0.81380597 | 0.069086302 | 0.005700326 |
| 18 | ExtraTreeClassifier | 0.895131086 | 0.813432836 | 0.047227664 | 0.003000212 |
| 0 | AdaBoostClassifier | 0.820411985 | 0.811940299 | 0.049860576 | 0.058903384 |
| 5 | GaussianProcessClassifier | 0.871722846 | 0.810447761 | 0.049253731 | 0.156008911 |
| 20 | QuadraticDiscriminantAnalysis | 0.821535581 | 0.807089552 | 0.081038901 | 0.005000305 |
| 8 | RidgeClassifierCV | 0.796629213 | 0.794029851 | 0.036030172 | 0.008900499 |
| 19 | LinearDiscriminantAnalysis | 0.796816479 | 0.794029851 | 0.036030172 | 0.007000422 |
| 16 | LinearSVC | 0.797565543 | 0.792910448 | 0.041053256 | 0.036402035 |
| 6 | LogisticRegressionCV | 0.797003745 | 0.790671642 | 0.065358182 | 0.127807283 |
| 12 | GaussianNB | 0.794756554 | 0.781343284 | 0.087456828 | 0.005600309 |
| 11 | BernoulliNB | 0.78576779 | 0.775373134 | 0.057034653 | 0.005900288 |
| 9 | SGDClassifier | 0.73670412 | 0.739179104 | 0.123788965 | 0.009600472 |
| 10 | Perceptron | 0.740074906 | 0.728731343 | 0.162220766 | 0.009200573 |
| 7 | PassiveAggressiveClassifier | 0.699812734 | 0.682462687 | 0.352227936 | 0.010100603 |
以图形化的方式将结果展示出来:1
2
3
4
5
6
7
8
9plt.figure(figsize=[16,12])
#barplot using https://seaborn.pydata.org/generated/seaborn.barplot.html
sns.barplot(x='MLA Test Accuracy Mean', y = 'MLA Name', data = MLA_compare, color = 'm')
#prettify using pyplot: https://matplotlib.org/api/pyplot_api.html
plt.title('Machine Learning Algorithm Accuracy Score \n')
plt.xlabel('Accuracy Score (%)')
plt.ylabel('Algorithm')
STEP 5.2. 选择基线
在进行后续的模型优化之前,我们首先需要判断目前所拥有的模型是否值得继续优化,因此我们要确定一个基线。
我们知道这是一个二分类问题,因此无论如何,就算是猜,最差也应该能够有 50% 的准确率。当然,这个基线是在对于具体的项目和数据信息一无所知的情况下确定的,但事实上我们对这个数据集有一定的了解。
我们知道在这个事故中,2224 人中有 1502 人丧生,也就是 67.5%。如果我们就单纯的猜测所有人全部丧生,那么也会有 67.5% 的准确率。因此我们的准确率要大于这个值才有价值,我们将这个基线设置为 68%。
参考
[1] https://www.kaggle.com/c/titanic
[2] https://www.kaggle.com/ldfreeman3/a-data-science-framework-to-achieve-99-accuracy/notebook