摘要 目前有数千万的数据存储在 MongoDB 中,单台机器、单库单表。要使用 Spark 处理,所以打算先转到 HBase 中。使用生产者消费者模式,利用多线程实现该功能。
主要内容 数据是爬虫爬取的一些问答数据,存储在 MongoDB 中,大概六七千万条,一百五十多G。单库单表。
由于数据读取和写入肯定是有速度差的,因此使用生产者消费者模式,利用线程进行均衡。采用三段式,分给读取数据ID、数据内容、写入。
读取 ID 由于数据量较大,肯定不能一次读取,因此需要采用类似分页的方式读取。MongoDB 中分页有两种方式,一种是 skip,直接跳过一定数量的数据,但这种方式如果要跳过较多数据量时性能很差。
因此采取设置起始行的方式进行分页。也就是读取 N 行数据,然后以第一批数据的最后一行为起点,读取下一批 N 行数据,这种方式的效率较高。
将所有读取的数据放入一个队列中,供后续线程处理。
读取内容 另外开辟线程读取 ID 后从 MongoDB 中读取数据内容。当初这样考虑的原因是考虑到读取数据和解析可能会耗费一些时间,因此可以多开两个线程处理这部分功能。不过实际测试发现,这部分处理的速度仍然非常快,基本上一万条数据在两百毫秒左右。
这部分读取的内容封装成对象之后,再放入一个队列中,供写入线程使用。
写入 写入是一个比较耗费时间的过程,一开始使用生产中消费者模式也是出于这个考虑。不过实际测试下来,基本上读取 ID 和内容都只要一个线程即可,而写入数据则需要多开辟几个线程,其速度是相当慢。
并且对于提高 HBase 写入性能还需要专门研究,我觉得这里还有很大的提升空间。
性能分析 通过日志记录对数据读写进行分析。其中读取部分主要是读取完整内容,单单读取ID的速度非常快,可以忽略。
读写数据分别在两组不同的机器上测试:
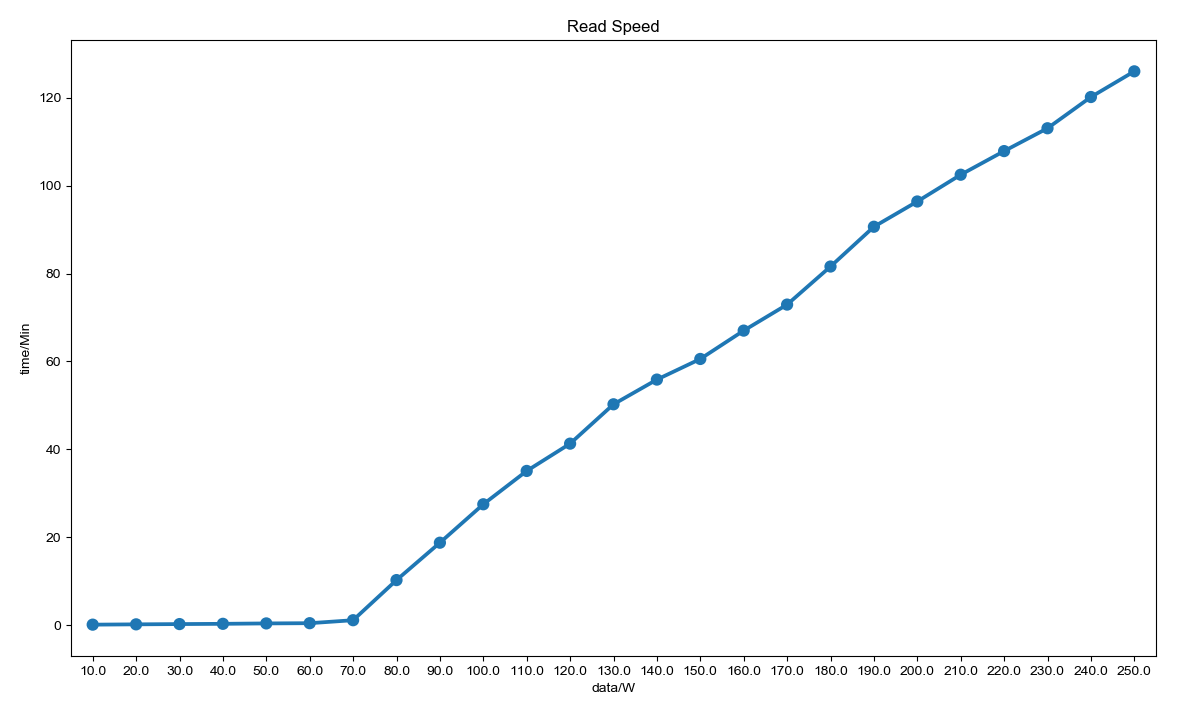
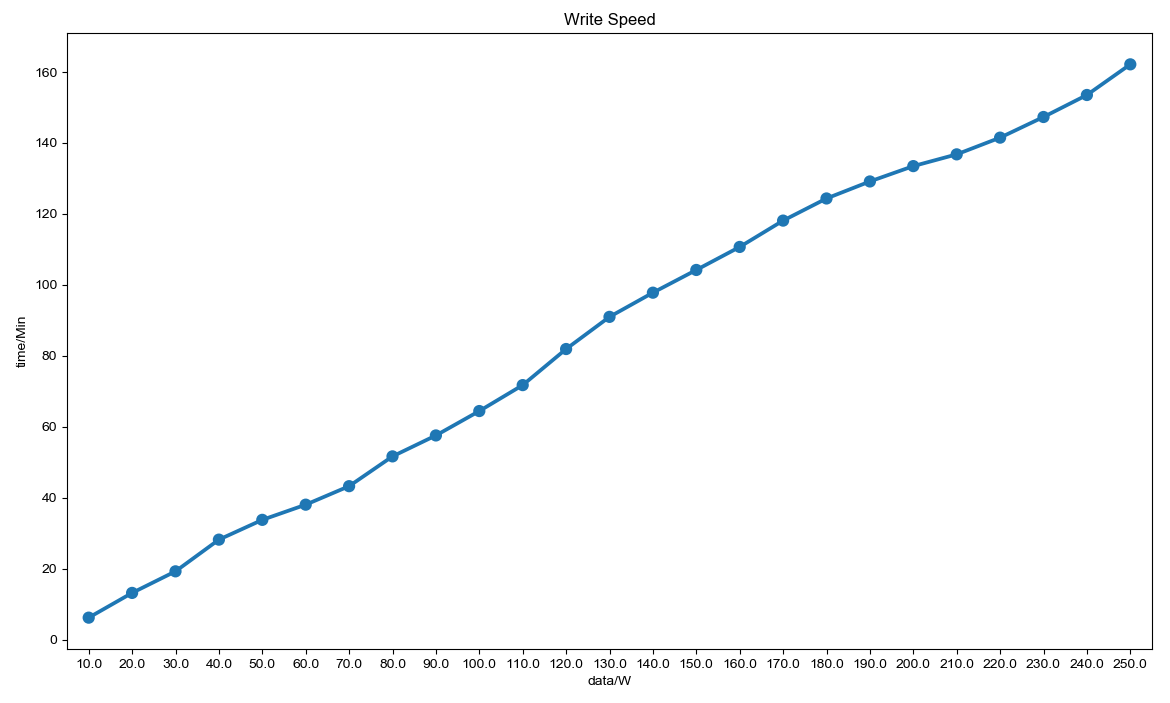
第一组机器 以 250W 条数据进行测试。
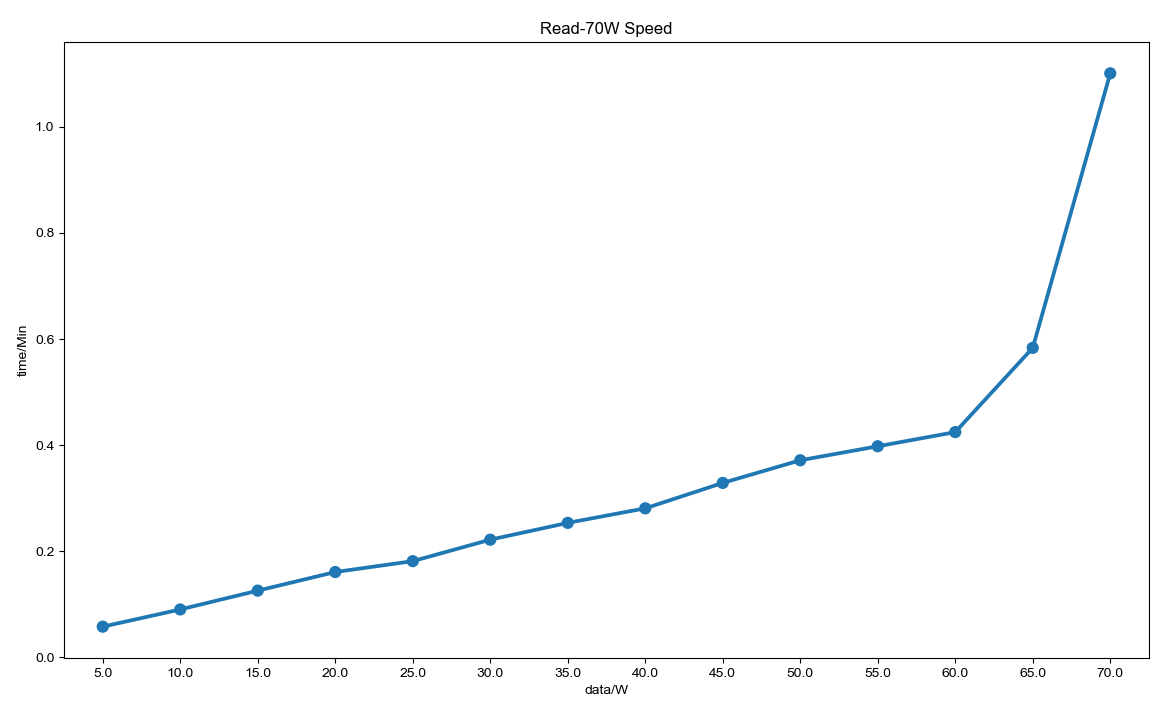
可以看到在 60W 左右,读取速度骤然下降:
推测这里应该是与 MongoDB 数据存储机制相关。MongDB 会将一部分数据缓存在内存中,写不下的会放到文件中。前面速度快的部分应该就是从内存中读取,后面速度骤然下降,就是从文件中读取了。
调研过 MongoDB 的数据缓存策略,是通过数据访问频繁程度控制的,无法进行手动调整,因此优化这部分性能的方法就在于提高物理内存了。该猜想可以在第二组机器测试结果里面得到验证。第二组机器内存较大,全程读取速度都非常快。
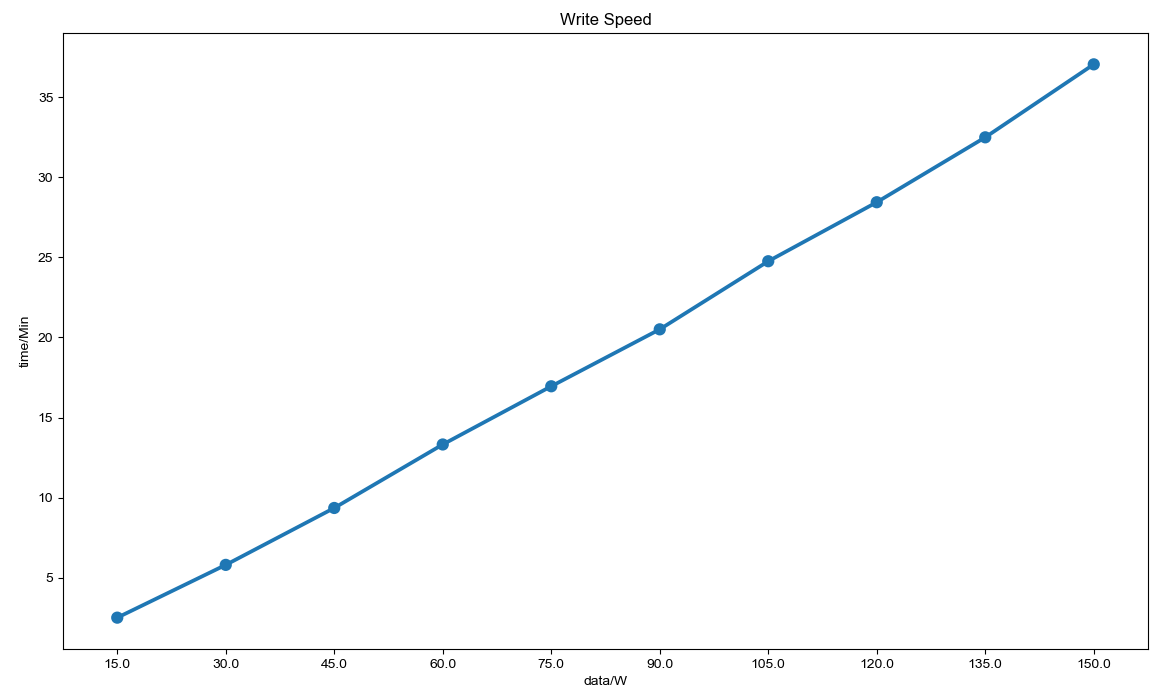
至于写入速度,就相对较慢了。主要瓶颈也在于此。开了三个线程,如果开更多,就会有部分写入线程被挂起,速度没有提升。HBase 的写入机制需要研究下,难道是每个 RegionServer 支持一个写入?如果是这样,写入的性能也不是很高啊。
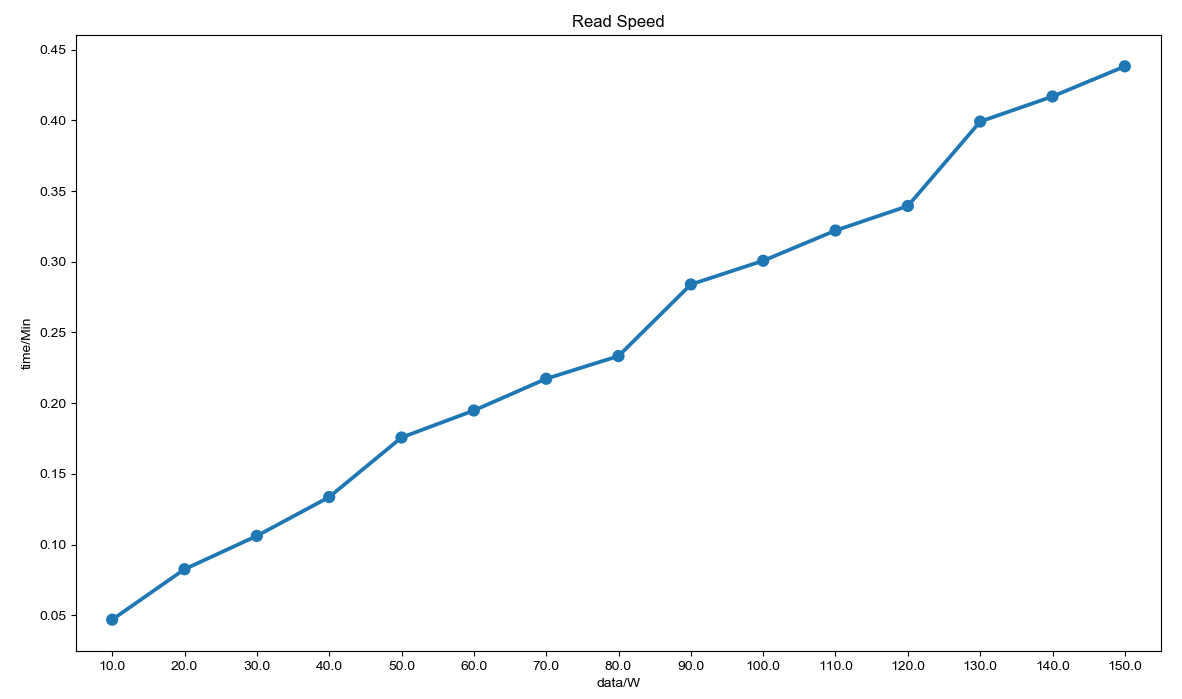
第二组机器 以 150W 条数据进行测试。
可以看到,其读取速度一直很稳定,相当快。
写入速度也要快一些,是因为多了两台 RegionServer 的原因么?
分析脚本 绘制分析折线图采用的是 Python 的 Seaborn 类库,需要安装 Python 环境。
脚本代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pandas as pddf = pd.read_csv("250W_read_70W.csv" ) ds = df[df['data/W' ] % 50000 == 0 ] ds['data/W' ] = ds['data/W' ] / 10000 ds['time/Min' ] = ds['time/Min' ] / 60000 import seaborn as snsimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif' ] =['Microsoft YaHei' ] f, ax= plt.subplots(figsize = (14 , 8 )) ax.set_title('Read-70W Speed' ) sns.set_style("darkgrid" ) sns.pointplot(x="data/W" ,y="time/Min" ,data=ds) plt.show()
项目介绍 项目采用基于 Maven 的 Java 控制台项目。
依赖 项目基于 JDK 1.8,另外主要还用到了 MongoDB 驱动、HBase Client、日志等类库。其 Maven 依赖如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-hdfs</artifactId > <version > 2.6.0</version > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > 2.6.0</version > </dependency > <dependency > <groupId > org.apache.hbase</groupId > <artifactId > hbase-client</artifactId > <version > 1.2.0</version > </dependency > <dependency > <groupId > org.mongodb</groupId > <artifactId > mongo-java-driver</artifactId > <version > 3.9.0</version > </dependency > <dependency > <groupId > org.slf4j</groupId > <artifactId > slf4j-api</artifactId > <version > 1.7.25</version > </dependency > <dependency > <groupId > ch.qos.logback</groupId > <artifactId > logback-classic</artifactId > <version > 1.2.3</version > </dependency > <dependency > <groupId > ch.qos.logback</groupId > <artifactId > logback-core</artifactId > <version > 1.2.3</version > </dependency >
Resources 目录 core-site.xml & hbase-site.xml 为了能够访问 HBase,需要在项目的 classpath 中加入目标集群的这两个文件。分别从 Hadoop 和 HBase 部署的配置目录中拷贝这两个文件到项目的 resources 目录中。
log4j.properties 日志配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # Set root logger level to DEBUG and its only appender to A1. log4j.rootLogger=INFO, STO, F # A1 is set to be a ConsoleAppender. log4j.appender.STO=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.STO.layout=org.apache.log4j.PatternLayout log4j.appender.STO.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} [%t] %-5p %c %x - %m%n log4j.appender.F=org.apache.log4j.DailyRollingFileAppender log4j.appender.F.File=./log.log log4j.appender.F.layout=org.apache.log4j.PatternLayout log4j.appender.F.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} [%t] %-5p %c %x - %m%n log4j.logger.com.oolong=DEBUG #log4j.logger.org.mongodb=ERROR
logback.xml 日志配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 <?xml version="1.0" encoding="UTF-8"?> <configuration debug ="false" scan ="true" scanPeriod ="30 seconds" packagingData ="true" > <contextName > MedicalQATransfer</contextName > <appender name ="STDOUT" class ="ch.qos.logback.core.ConsoleAppender" > <encoder > <pattern > %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern > </encoder > </appender > <appender name ="FILE" class ="ch.qos.logback.core.rolling.RollingFileAppender" > <file > ./medicalqatransfer.log</file > <rollingPolicy class ="ch.qos.logback.core.rolling.TimeBasedRollingPolicy" > <FileNamePattern > ./medicalqatransfer%d{yyyyMMdd}.log.zip</FileNamePattern > <maxHistory > 30</maxHistory > </rollingPolicy > <encoder > <pattern > %d{yyyy-MM-dd HH:mm:ss.SSS}[%-5level][%thread]%logger{36} - %msg%n</pattern > </encoder > </appender > <logger name ="com.oolong" level ="DEBUG" > <appender-ref ref ="STDOUT" /> <appender-ref ref ="FILE" /> </logger > <root level ="debug" > <appender-ref ref ="STDOUT" /> <appender-ref ref ="FILE" /> </root > </configuration >
程序入口 App 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 package com.oolong;import com.oolong.model.QAModel;import com.oolong.read.ReadDocumentsTask;import com.oolong.read.ReadIdsTask;import com.oolong.write.WriteTask;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;import java.io.IOException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingQueue;import java.util.concurrent.atomic.AtomicInteger;import java.util.concurrent.atomic.AtomicLong;public class App public static void main ( String[] args ) throws IOException String path = new File("." ).getCanonicalPath(); System.getProperties().put("hadoop.home.dir" , path); new File("./bin" ).mkdirs(); new File("./bin/winutils.exe" ).createNewFile(); Logger logger = LoggerFactory.getLogger(App.class); LinkedBlockingQueue<String> idPool = new LinkedBlockingQueue<>(); AtomicInteger count = new AtomicInteger(0 ); AtomicInteger savedCount = new AtomicInteger(0 ); AtomicLong start = new AtomicLong(System.currentTimeMillis()); logger.info("Create Thread: Load Ids from MongoDB." ); Thread idReadTask = new Thread(new ReadIdsTask(idPool, 1000000 )); idReadTask.start(); logger.info("Starting Thread: Load Ids from MongoDB..." ); logger.info("Create Thread: Load QAData from MongoDB." ); LinkedBlockingQueue<QAModel> questionPool = new LinkedBlockingQueue<>(); ExecutorService docReadTask = Executors.newCachedThreadPool(); for (int i = 0 ; i < 1 ; i++) { docReadTask.execute(new ReadDocumentsTask(idPool, questionPool , 100 , count, start)); } logger.info("Starting Thread: Load QAData from MongoDB..." ); ExecutorService docSaveTask = Executors.newCachedThreadPool(); for (int i = 0 ; i < 3 ; i++) { docReadTask.execute(new WriteTask(questionPool , 1000 , savedCount, start)); } logger.info("Starting Thread: Save QAData to HBase..." ); } }
主要逻辑 ReadIdsTask 读取 ID 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 package com.oolong.read;import com.mongodb.client.FindIterable;import com.mongodb.client.MongoCollection;import com.mongodb.client.MongoCursor;import com.oolong.utils.MongoUtil;import org.bson.Document;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.ArrayList;import java.util.List;import java.util.concurrent.LinkedBlockingQueue;public class ReadIdsTask implements Runnable private LinkedBlockingQueue<String> idPool; private int capacity; private int batchNum; private String start; private Logger logger; public ReadIdsTask (LinkedBlockingQueue<String> idPool, int capacity) this .idPool = idPool; this .capacity = capacity; this .start = "" ; this .batchNum = 10000 ; this .logger = LoggerFactory.getLogger(ReadIdsTask.class); } @Override public void run () MongoCollection<Document> collection = MongoUtil.getCollection(); while (true ) { try { if (capacity - idPool.size() < batchNum) { Thread.sleep(1000 ); continue ; } List<String> ids = this .readBatchIds(collection, start, batchNum); if (ids.size() > 0 ) { this .start = ids.get(ids.size() - 1 ); idPool.addAll(ids); logger.info("当前待处理ID: " + idPool.size()); } else { logger.info("完成所有Id加载,结束当前任务。" ); break ; } } catch (InterruptedException e) { logger.debug(e.getMessage()); } } } private List<String> readBatchIds (MongoCollection<Document> collection, String start, int num) FindIterable<Document> findIterable = null ; Document fieldFilter = new Document("_id" , 1 ); if (!start.isEmpty()) { Document condition = new Document("_id" , new Document("$gt" , start)); findIterable = collection.find(condition).projection(fieldFilter).limit(num); } else { findIterable = collection.find().projection(fieldFilter).limit(num); } MongoCursor<Document> mongoCursor = findIterable.iterator(); List<String> res = new ArrayList<>(); while (mongoCursor.hasNext()){ res.add(mongoCursor.next().getString("_id" )); } return res; } }
ReadDocumentsTask 读取内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 package com.oolong.read;import com.mongodb.client.FindIterable;import com.mongodb.client.MongoCollection;import com.mongodb.client.MongoCursor;import com.oolong.model.Answer;import com.oolong.model.QAModel;import com.oolong.utils.MongoUtil;import org.bson.Document;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.ArrayList;import java.util.List;import java.util.concurrent.LinkedBlockingQueue;import java.util.concurrent.atomic.AtomicInteger;import java.util.concurrent.atomic.AtomicLong;public class ReadDocumentsTask implements Runnable private LinkedBlockingQueue<String> idPool; private LinkedBlockingQueue<QAModel> questionPool; private int batchNum; private AtomicInteger count; private AtomicLong start; private Logger logger; public ReadDocumentsTask (LinkedBlockingQueue<String> idPool , LinkedBlockingQueue<QAModel> questionPool, int batchNum , AtomicInteger count, AtomicLong start) this .idPool = idPool; this .questionPool = questionPool; this .batchNum = batchNum; this .count = count; this .start = start; this .logger = LoggerFactory.getLogger(ReadDocumentsTask.class + Thread.currentThread().getName()); } @Override public void run () MongoCollection<Document> collection = MongoUtil.getCollection(); List<String> ids = null ; while (true ) { try { if (idPool.size() <= 0 ) { Thread.sleep(500 ); continue ; } ids = new ArrayList<>(); int num = Math.min(idPool.size(), batchNum); for (int i = 0 ; i <num; i++) { ids.add(idPool.poll()); } List<QAModel> qas = this .readDocument(collection, ids); questionPool.addAll(qas); count.addAndGet(qas.size()); logger.info("读取数据: " + count + " 耗费时间: " + (System.currentTimeMillis() - start.get()) + "ms" ); } catch (InterruptedException e) { logger.debug(e.getMessage()); } } } private List<QAModel> readDocument (MongoCollection<Document> collection, List<String> ids) Document condition = new Document("_id" , new Document("$in" , ids)); FindIterable<Document> findIterable = collection.find(condition); MongoCursor<Document> mongoCursor = findIterable.iterator(); List<QAModel> res = new ArrayList<>(); QAModel model = null ; Answer answer = null ; Document document = null ; while (mongoCursor.hasNext()){ model = new QAModel(); document = mongoCursor.next(); model.setId(document.getString("_id" )); List<Document> ans = (ArrayList<Document>)document.get("answers" ); for (Document a : ans) { answer = new Answer(); answer.setAnswer(a.getString("answer" )); model.getAnswers().add(answer); } res.add(model); } return res; } }
WriteTask 写入 HBase 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 package com.oolong.write;import com.oolong.model.Answer;import com.oolong.model.QAModel;import com.oolong.utils.HBaseUtil;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Table;import org.apache.hadoop.hbase.util.Bytes;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.IOException;import java.util.ArrayList;import java.util.List;import java.util.concurrent.LinkedBlockingQueue;import java.util.concurrent.atomic.AtomicInteger;import java.util.concurrent.atomic.AtomicLong;public class WriteTask implements Runnable private LinkedBlockingQueue<QAModel> questionPool; private int batchNum; private AtomicInteger savedCount; private AtomicLong start; private Logger logger; public WriteTask (LinkedBlockingQueue<QAModel> questionPool, int batchNum , AtomicInteger savedCount, AtomicLong start) this .questionPool = questionPool; this .batchNum = batchNum; this .savedCount = savedCount; this .start = start; this .logger = LoggerFactory.getLogger(WriteTask.class + Thread.currentThread().getName()); } @Override public void run () Table table = null ; while (true ) { try { if (table == null ) { table = HBaseUtil.getTable(); Thread.sleep(1000 ); } else { break ; } } catch (InterruptedException e) { logger.debug(e.getMessage()); } } while (true ) { try { if (questionPool.size() <= 0 ) { Thread.sleep(1000 ); continue ; } List<QAModel> questions = new ArrayList<>(); int num = Math.min(questionPool.size(), batchNum); for (int i = 0 ; i < num; i++) { questions.add(questionPool.poll()); } writeToHBase(table, questions); savedCount.addAndGet(questions.size()); logger.info("保存数据: " + savedCount + " 耗费时间: " + (System.currentTimeMillis() - start.get()) + "ms" ); } catch (InterruptedException e) { logger.debug(e.getMessage()); } } } private void writeToHBase (Table table, List<QAModel> questions) try { List<Put> actions = new ArrayList<>(); for (QAModel model : questions) { Put put = new Put(Bytes.toBytes(model.getId())); put.addColumn(Bytes.toBytes("http" ), Bytes.toBytes("url" ), Bytes.toBytes(model.getUrl())); actions.add(put); } table.put(actions); } catch (IOException e) { logger.debug(e.getMessage()); } } }
工具类 Constant 常量 1 2 3 4 5 6 7 8 9 10 package com.oolong.utils;public class Constant public static String MONGO_IP = "192.168.0.125" ; public static int MONGO_PORT = 27017 ; public static String MONGO_DB = "medicalqa_8" ; public static String MONGO_COLLECTION = "questions_2" ; public static String HB_TABLE = "medicalqa" ; }
MongoUtil MongoDB 连接工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.oolong.utils;import com.mongodb.MongoClient;import com.mongodb.client.MongoCollection;import com.mongodb.client.MongoDatabase;import org.bson.Document;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class MongoUtil private static Logger logger; static { logger = LoggerFactory.getLogger(MongoUtil.class); } public static MongoCollection<Document> getCollection () MongoClient mongo = new MongoClient(Constant.MONGO_IP, Constant.MONGO_PORT); MongoDatabase database = mongo.getDatabase(Constant.MONGO_DB); logger.info("Connect to MongoDB successfully" ); MongoCollection<Document> collection = database.getCollection(Constant.MONGO_COLLECTION); return collection; } }
HBaseUtil HBase 连接工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.oolong.utils;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.client.Table;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.IOException;import java.net.URISyntaxException;public class HBaseUtil private static Logger logger; static { logger = LoggerFactory.getLogger(HBaseUtil.class); } public static Table getTable () Table table = null ; try { Configuration config = HBaseConfiguration.create(); config.addResource(new Path(ClassLoader.getSystemResource("hbase-site.xml" ).toURI())); config.addResource(new Path(ClassLoader.getSystemResource("core-site.xml" ).toURI())); Connection connection = ConnectionFactory.createConnection(config); table = connection.getTable(TableName.valueOf(Constant.HB_TABLE)); logger.info("Connect to HBase successfully" ); } catch (URISyntaxException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return table; } }