摘要
使用 Idea 集成 Sbt 配置 Scala 开发环境,开发 Spark 程序。
配置基本环境
首先需要几个基本环境,一个是 JDK,还有 Scala,另外安装 Idea,以及在 Idea 中安装 Scala 插件,这里就不赘述了。
创建项目
首先创建一个 Scala - sbt 项目:
填写项目名称,项目路径。另外需要注意的是选择合适的 sbt 和 scala 版本。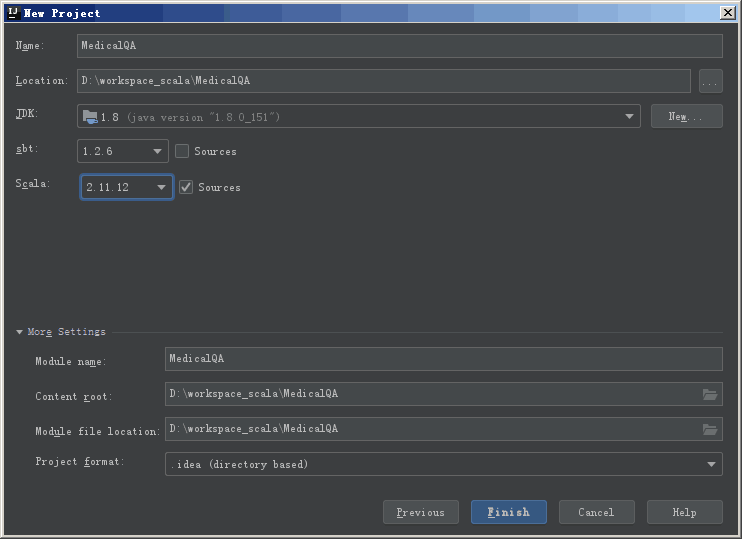
创建完成之后,会从远处服务器拉取项目结构信息,可能会耗费一些时间。
完成之后会生成如图所示的一个项目结构: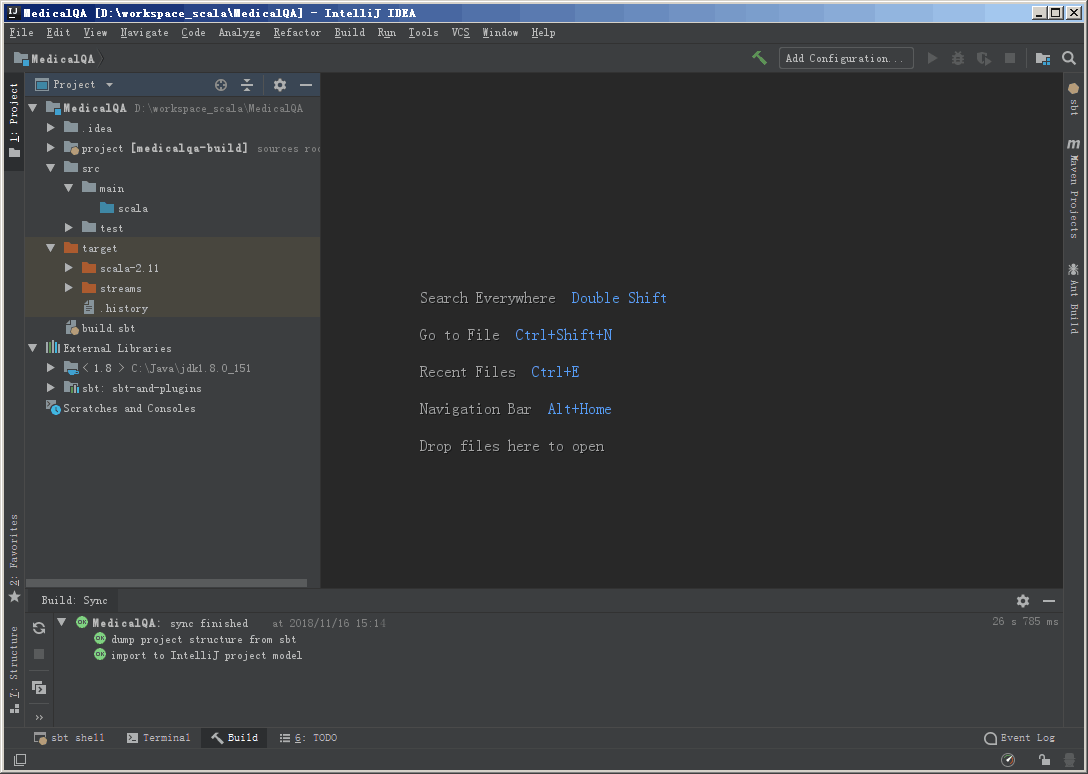
导入依赖
编辑 build.sbt 文件,填写项目依赖,这里是 Spark 程序,需要添加 Spark-core依赖。另外这里还声明了 Scala 依赖。
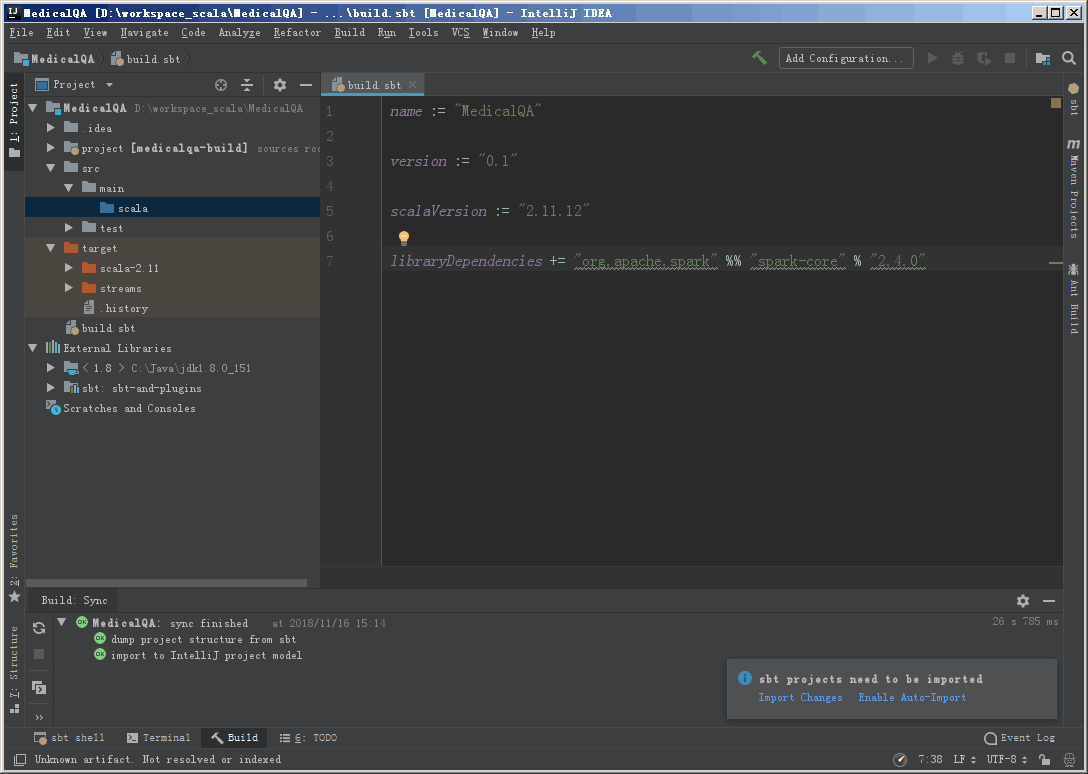
1 | name := "MedicalQA" |
在编辑了 build.sbt 文件后,会提示是否导入这些依赖,选择自动导入即可。
如果是第一次添加某个依赖,会从远程服务器下载,根据网络情况,耗费一定时间,需耐心等待。
导入之后,可以在 External Libraries 中看到这些依赖。
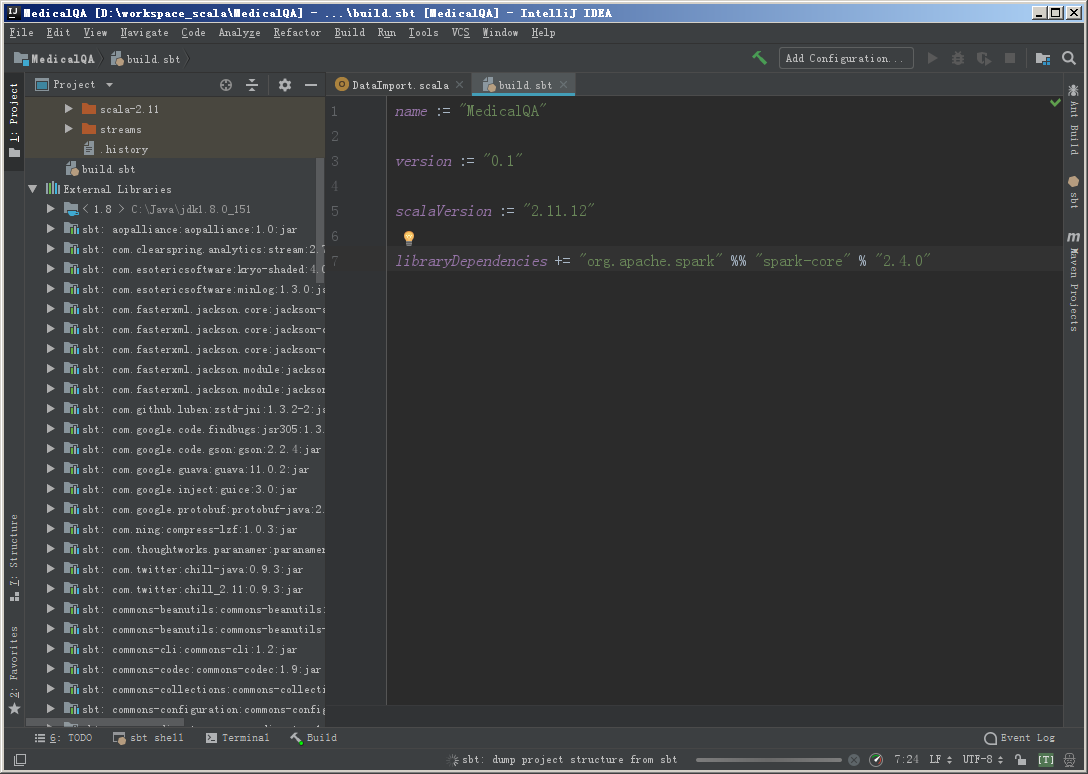
添加 SBT 依赖
如果 External Libraries 中没有 sbt 相关的 JAR 包,可以手动添加。
打开 Project Structure,在 File 或者界面右上角的文件图标打开。
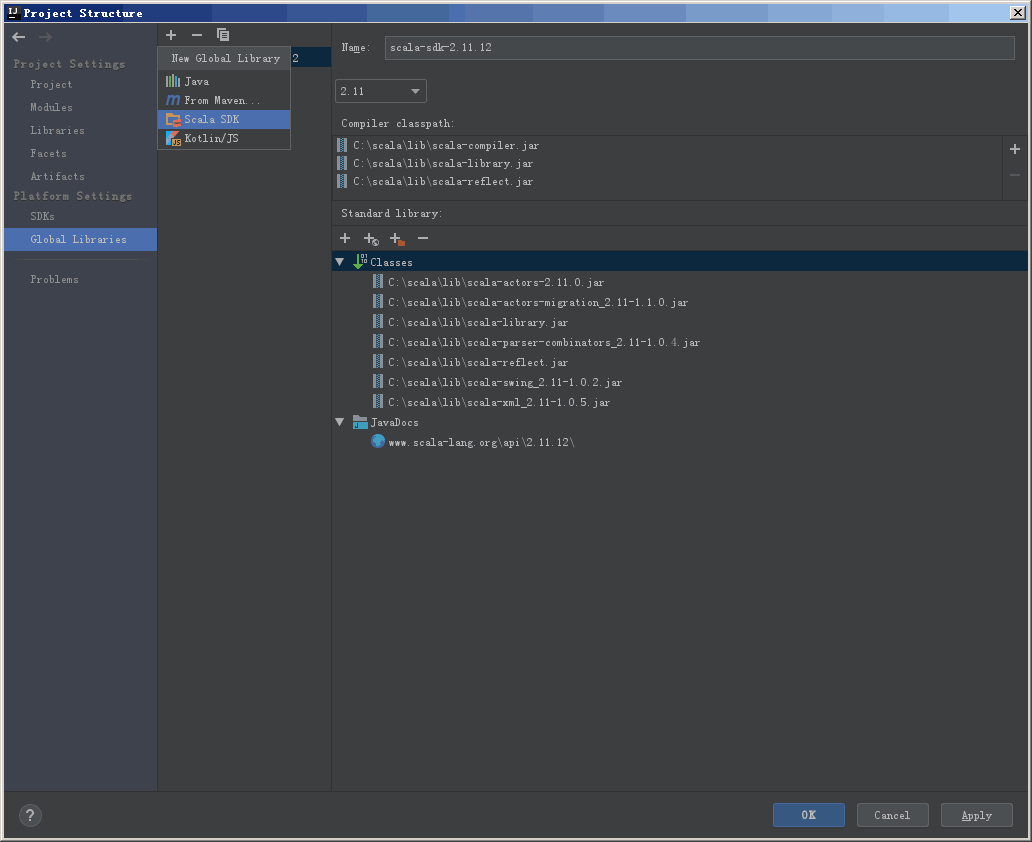
点击上方的小加号,选择 Scala SDK,图片中的实例是添加后的效果,一开始应该是空的。
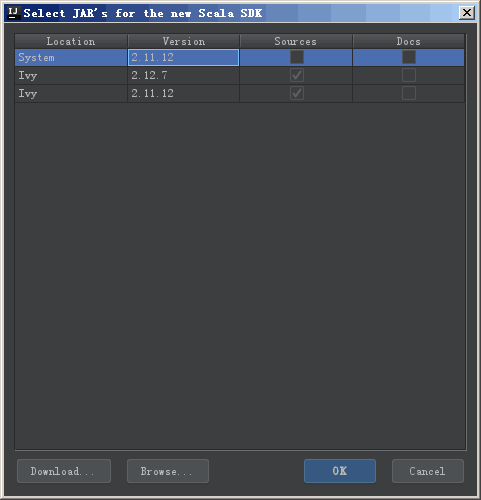
在弹出的如下界面中选择 Browse,浏览本地目录,选中本地 Scala 的根目录即可。
编写测试程序
创建一个 Scala 文件。
这里面写了一个小李子,是在hdfs上写入一个文本文件。完成之后就需要将项目编译成一个JAR包,上传到spark中执行。
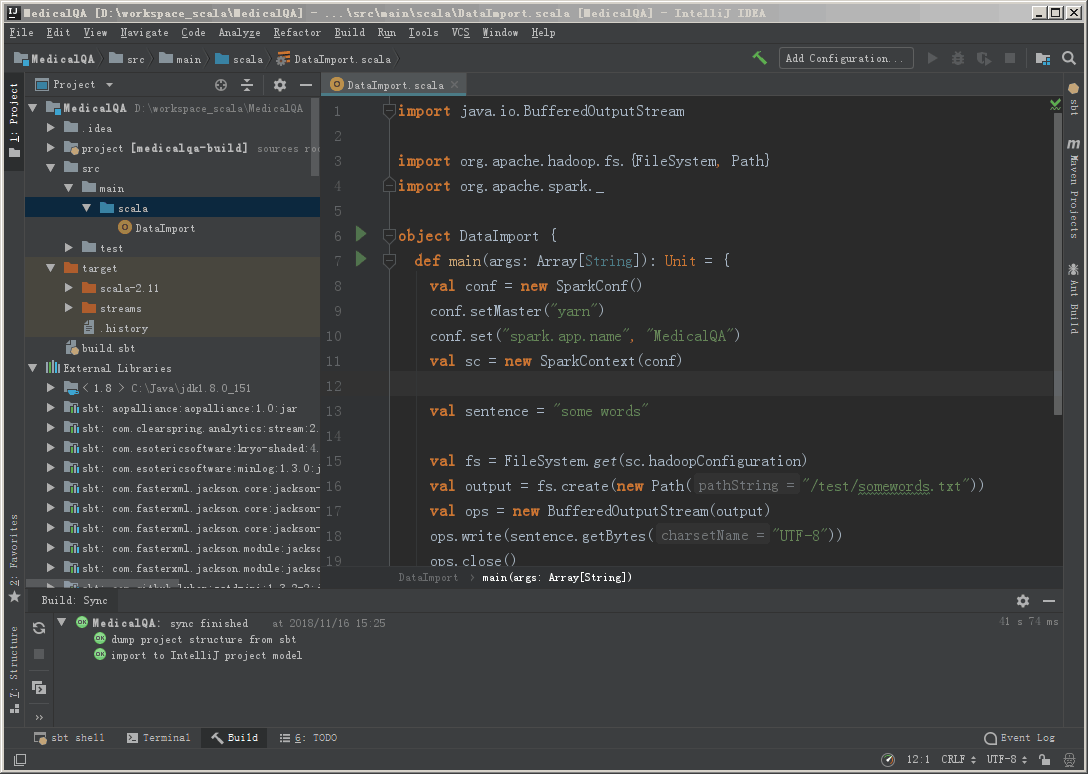
1 | import java.io.BufferedOutputStream |
编译打包
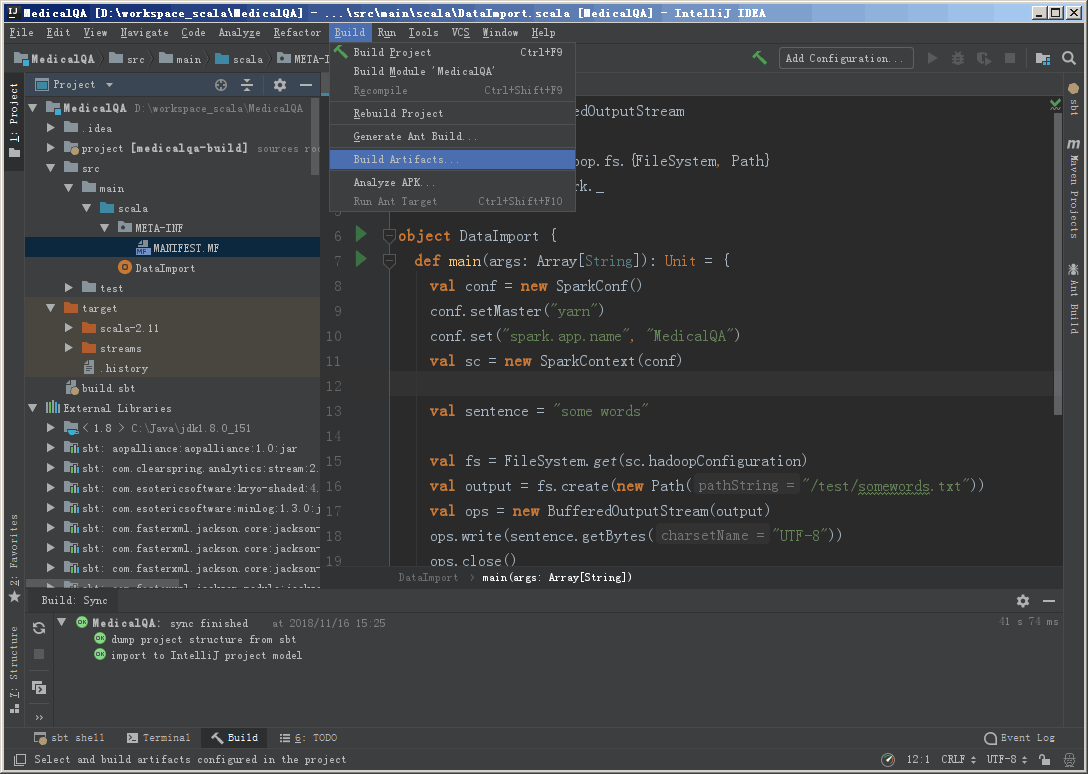
再次打开 Project Structure,选择 Artifacts,点击小加号
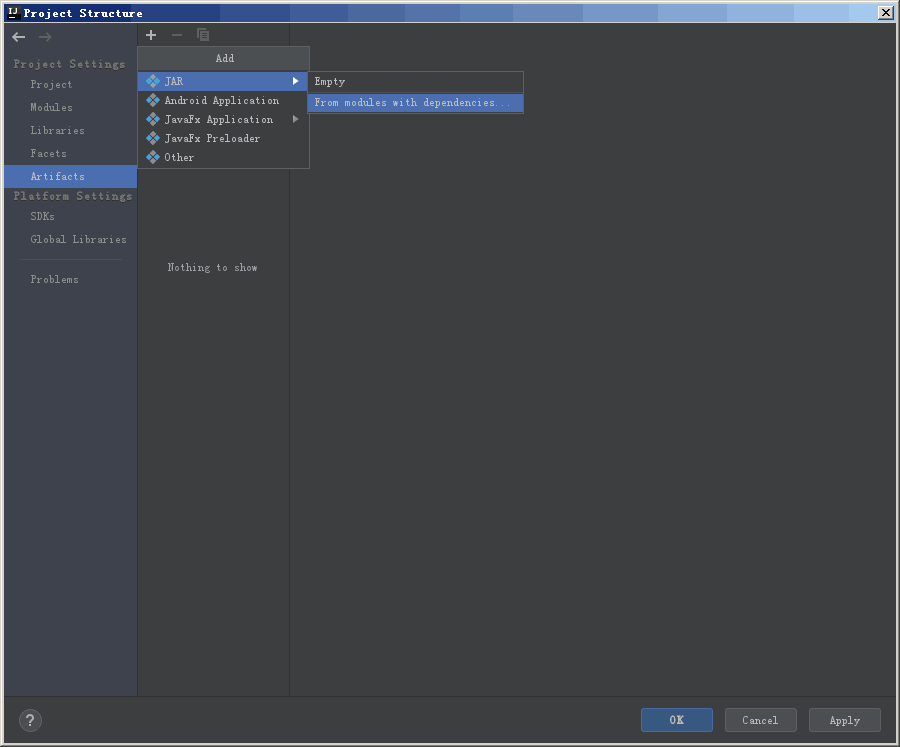
选择 Module,也就是项目,以及程序入口 Main Class,也就是主函数所在的类。
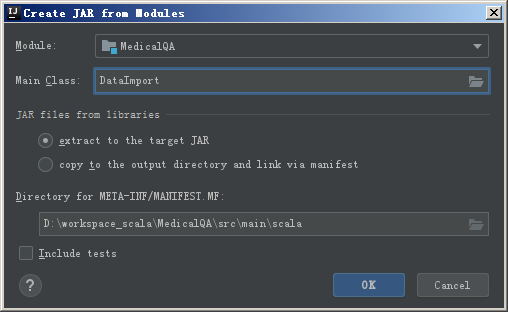
然后会看到如下的界面:
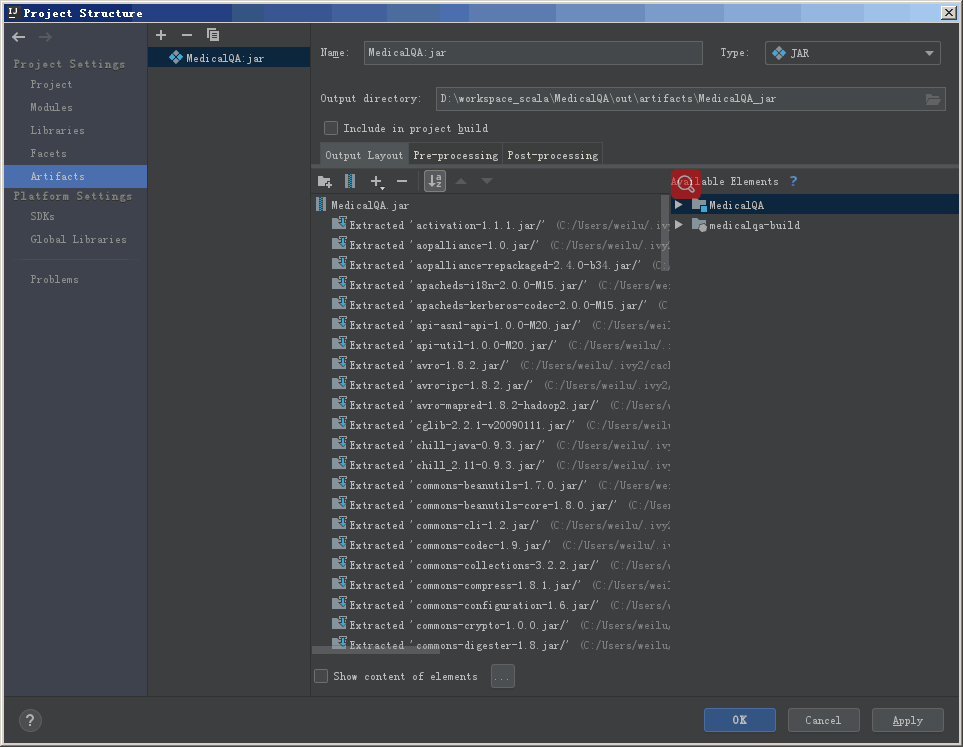
接下来我们要把jar包中引用的jar包去除掉,不打包在里面。选中这些JAR包,用上面的减号删除掉。
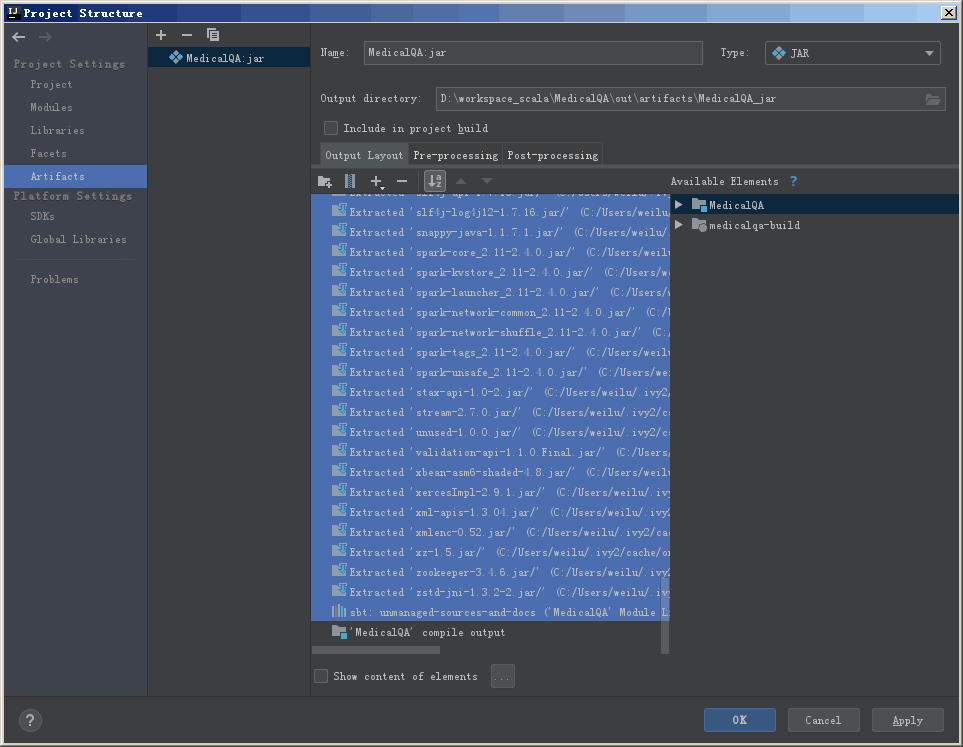
最后只剩下项目的代码
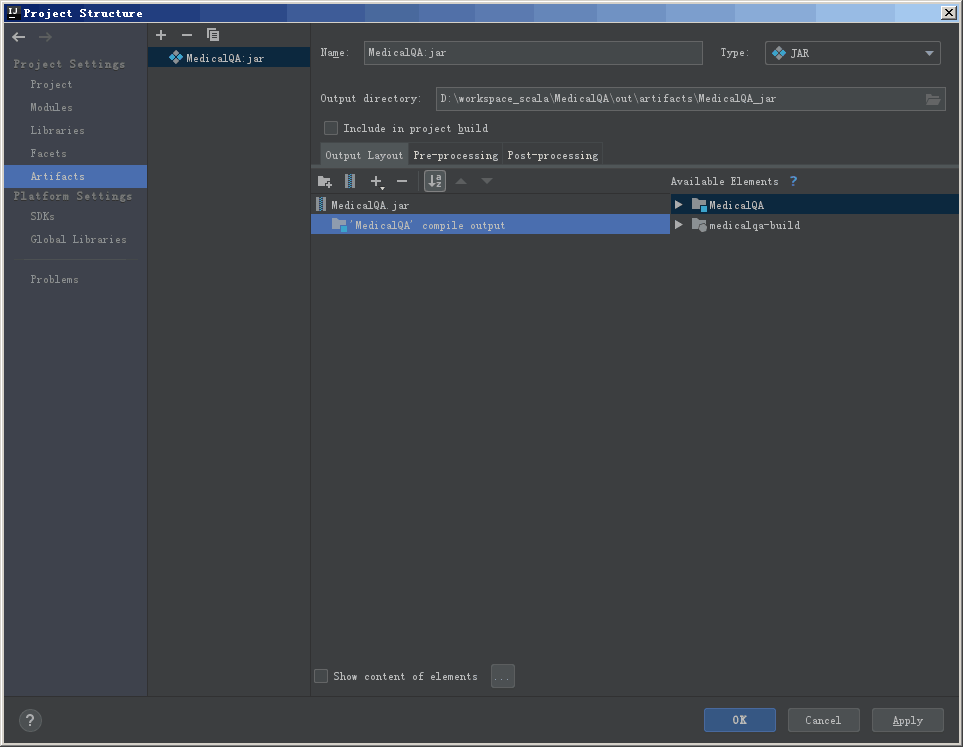
完成之后会在项目目录下看到 META-INF 目录。
然后进行编译。
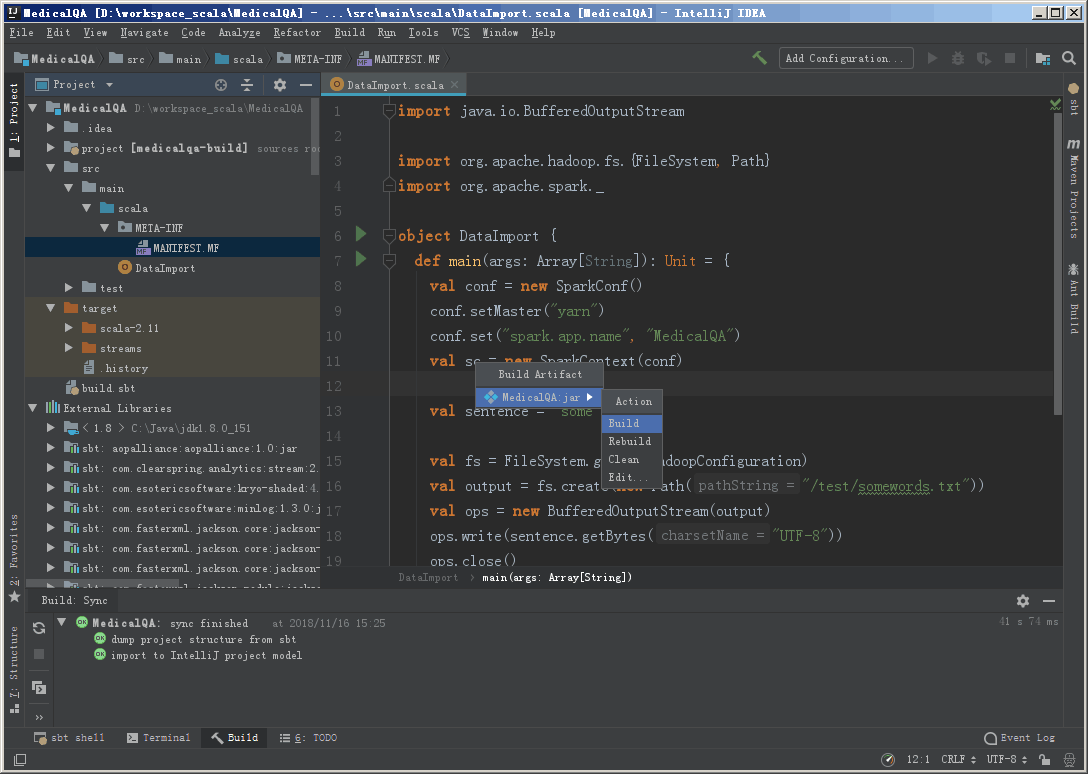
编译打包完成之后,会在项目目录中看到打包的结果
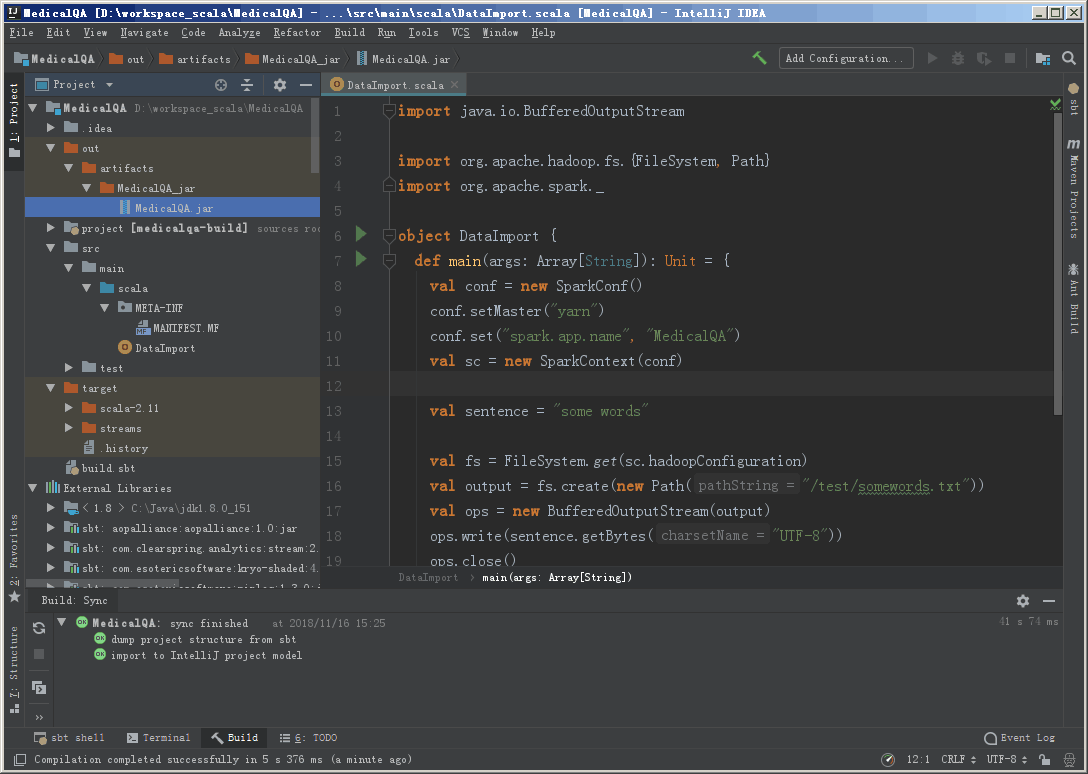
运行测试
接下来我们把这个JAR包提交到spark集群中跑跑看。
把 JAR 包放到 /home/workspace 目录下,执行命令:
1 | /usr/local/spark-2.4.0-bin-hadoop2.6/bin/spark-submit --class "DataImport" --deploy-mode cluster /home/workspace/MedicalQA.jar |
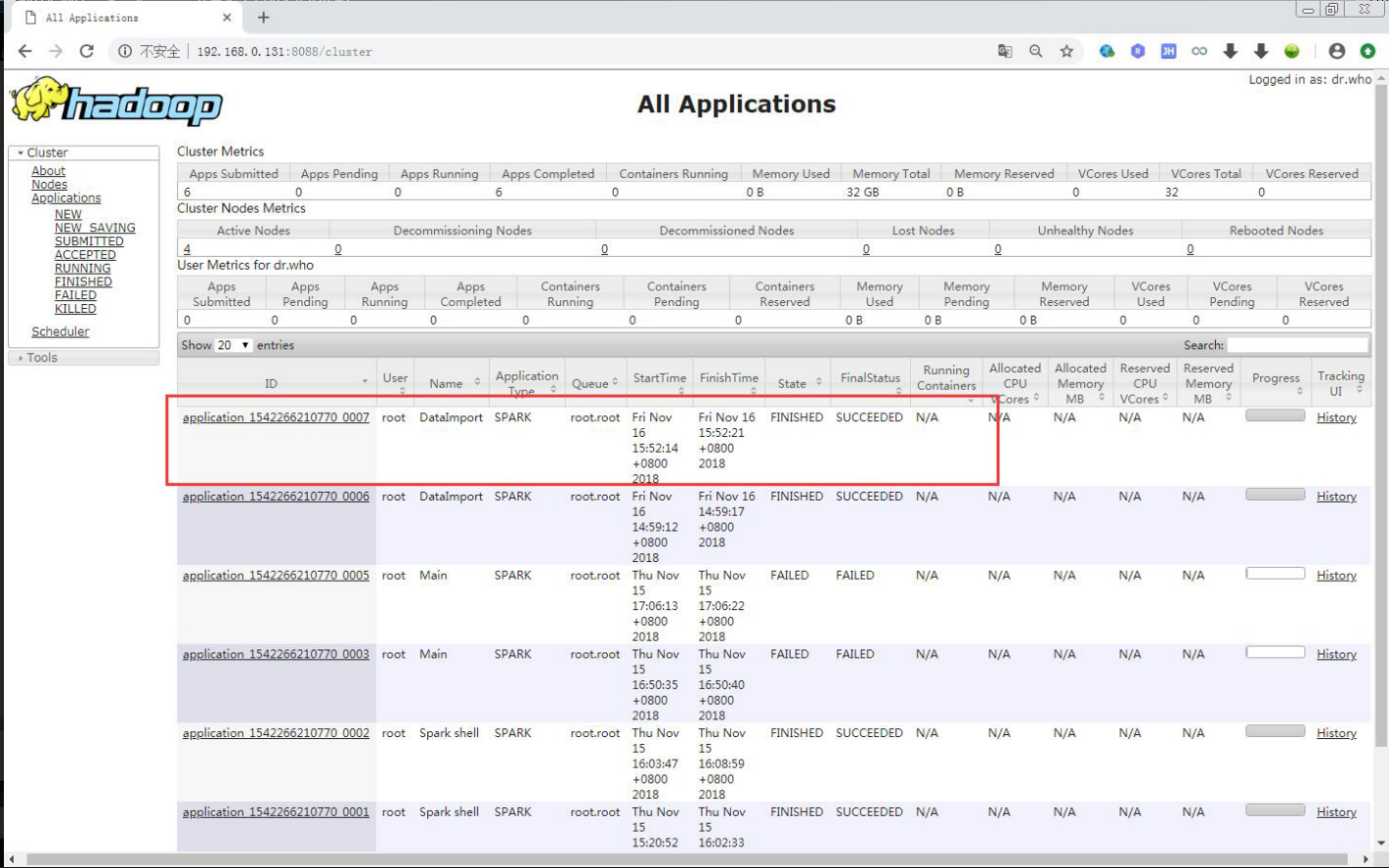
跑完之后如果没有报什么错的话,用HDFS命令检查一下
1 | [root@weilu131 bin]# ./hdfs dfs -ls /test |
发现文件确实写进去了,当然如果不放心还可以看看文件内容
1 | [root@weilu131 bin]# ./hdfs dfs -cat /test/somewords.txt |
还可以看看 Yarn 上面提交的任务执行情况