摘要
基于 Hadoop 和 Yarn 集群部署 Spark 集群。
部署 Scala
下载 Scala,放置到 /usr/local/ 下,并解压。1
tar -zxvf scala-2.11.12.tgz
配置环境变量:1
vim /etc/profile
中增加以下内容:1
2export SCALA_HOME=/usr/local/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
重新载入:1
source /etc/profile
验证:1
2
3
4
5[root@weilu131 local]# scala
Welcome to Scala 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_192).
Type in expressions for evaluation. Or try :help.
scala>
部署 Spark
下载&解压
从 Apache Spark download page 下载安装包。在选择安装包类型时,如果是针对某个版本的 Hadoop 的话,可以选择 Pre-build for Apache Hadoop 2.6,或 Pre-build for Apache Hadoop 2.7 and later。分别是针对 2.6 和 2.7 版本的。或者也可以选择 Pre-build with user-provided Apache Hadoop,表示适用于所有版本 Hadoop。
下载后解压到 /usr/local/ 目录。1
tar -zxvf spark-2.4.0-bin-hadoop2.6.tgz
开放端口
8080:Master节点上的端口,提供Web UI
8081:Worker节点上的端口,提供Web UI
1 | firewall-cmd --add-port=8080/tcp --permanent |
配置环境变量
在 Spark 的 conf 目录下拷贝一份 spark-env.sh 文件:1
cp spark-env.sh.template spark-env.sh
在文件最后添加以下内容:1
2
3
4
5
6
7
8
9
10export JAVA_HOME=/usr/local/jdk1.8.0_181
export SCALA_HOME=/usr/local/scala-2.11.12
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.15.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_WORKING_MEMORY=1g #每一个worker节点上可用的最大内存
export SPARK_MASTER_IP=weilu131 #驱动器节点IP
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hadoop classpath)
HADOOP_CONF_DIR
要让 Spark 与 YARN 资源管理器通信的话,需要将 Hadoop 的配置信息告诉 Spark,通过配置 HADOOP_CONF_DIR 环境变量实现。
设置 Yarn 为资源管理器
将 conf 目录下的配置文件模板拷贝一份:1
cp spark-defaults.conf.template spark-defaults.conf
修改其中的 master 配置:1
spark.master yarn
配置公共 JAR 包
配置 Spark 的 jar 包。在配合 Hadoop 集群下提交任务时,会将 jar 包提交到 HDFS 上,为防止每次提交任务时都提交,所以在 HDFS 上上传一份公共的。
在 HDFS 上创建存放 jar 包的目录:1
/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs dfs -mkdir /spark_jars
检查目录是否创建:1
/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs dfs -ls /
将 spark 下的 jar 包上传到该目录下:1
/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs dfs -put /usr/local/spark-2.4.0-bin-hadoop2.6/jars/* /spark_jars
使用如下命令检查是否上传成功:1
/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs dfs -ls /spark_jars
在 spark-defaults.conf 中增加以下内容:1
spark.yarn.jars hdfs://weilu131:9000/spark_jars/*
配置 slaves
配置从节点主机名(或者IP),在 Spark 的 conf 目录下拷贝一份 slaves 文件:1
cp slaves.template slaves
在其中添加以下内容:1
2
3weilu132
weilu135
weilu151
启动 Spark 集群
1 | /usr/local/spark-2.4.0-bin-hadoop2.6/sbin/start-all.sh |
验证
jps 命令
在 Master 和 Worker 节点上分别使用 jps 命令,可以分别看到 Master 和 Worker 进程。
Web UI
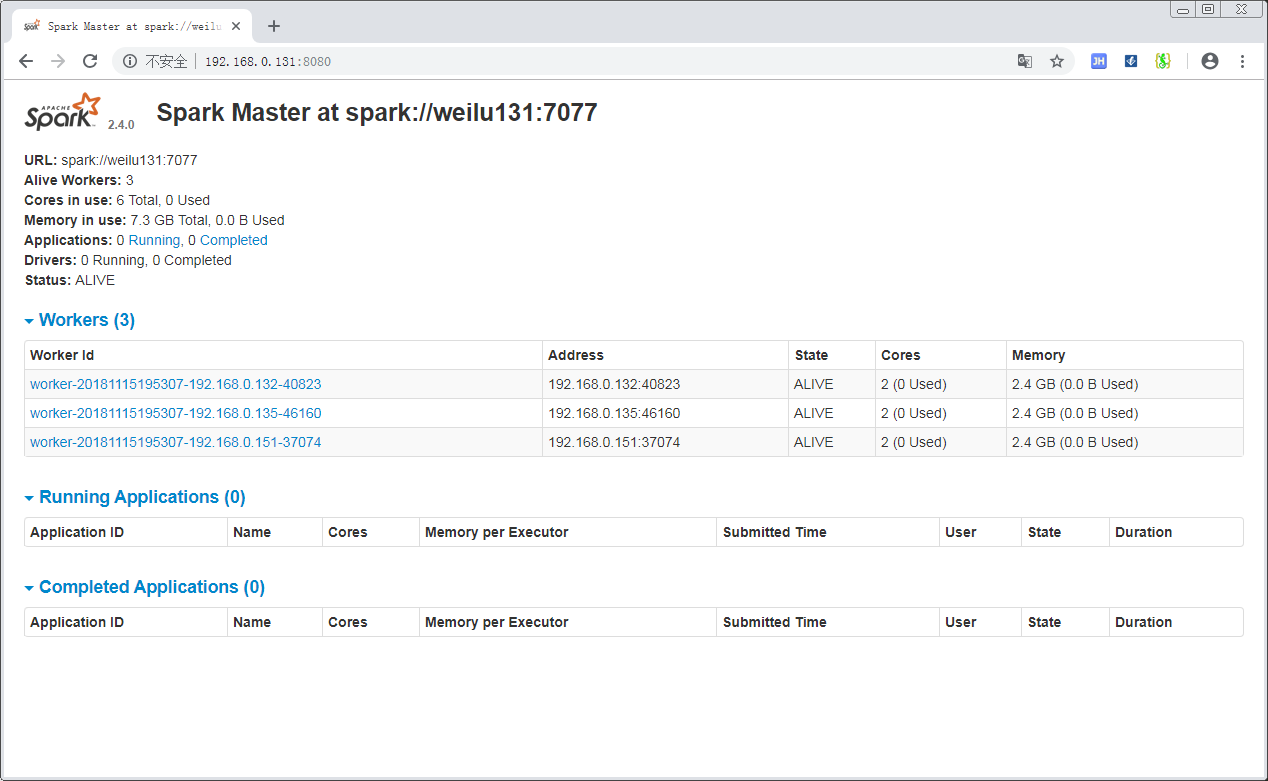
访问Master:http://192.168.0.131:8080/
可以看到当前集群的状况。
启动 spark-shell
Spark-shell 是 spark 提供的一个交互式编程环境,基于 Scala。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24[root@weilu131 conf]# /usr/local/spark-2.4.0-bin-hadoop2.6/bin/spark-shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/spark-2.4.0-bin-hadoop2.6/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.6.0-cdh5.15.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2018-11-15 19:57:20 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://weilu131:4040
Spark context available as 'sc' (master = yarn, app id = application_1542209821671_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
如果能够正常进入 scala 交互命令行,说明部署没有问题。
对于Yarn而言,实际上 spark-shell 也是一个应用程序,因此可以在Yarn上看到这个启动的 shell: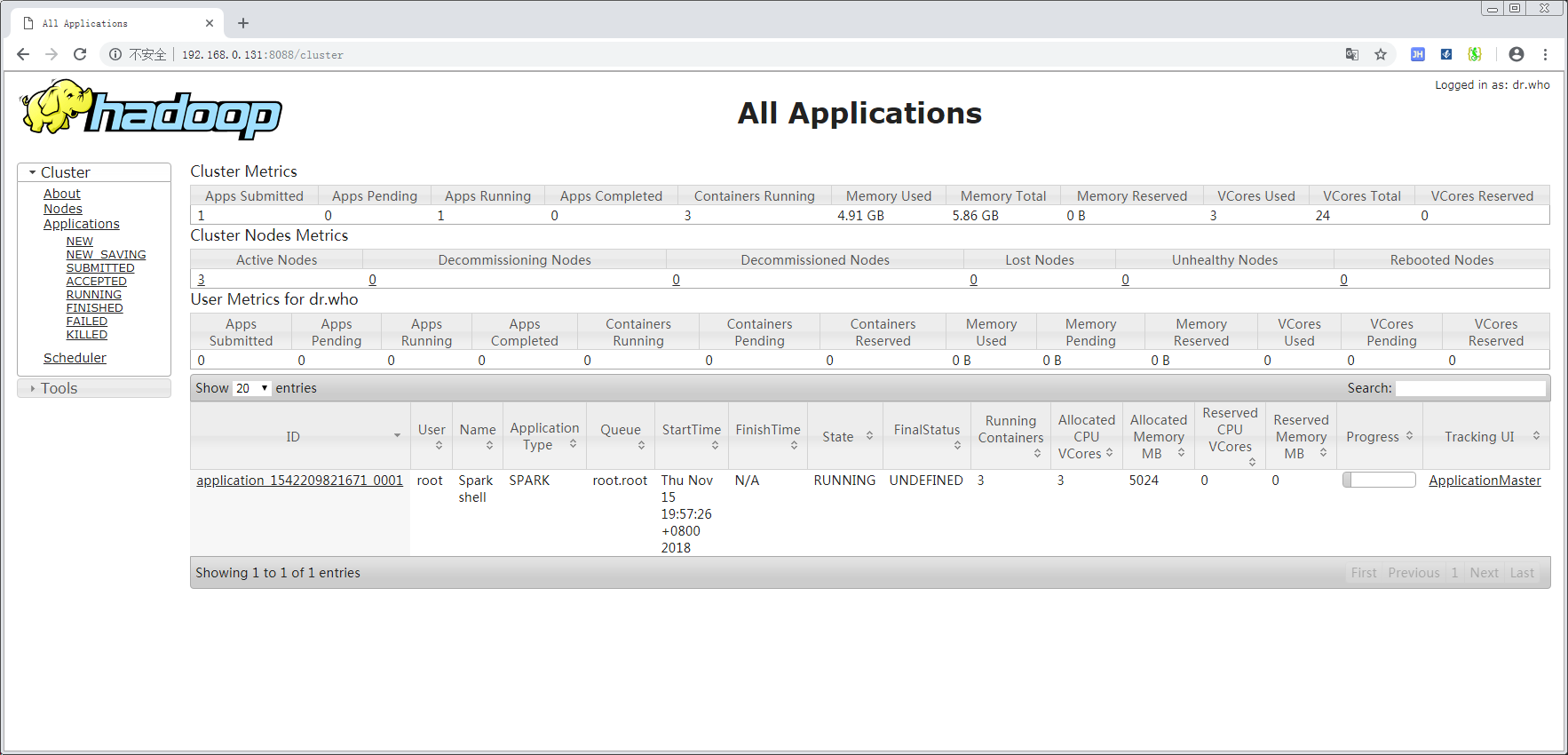
部署History Server(不完整)
该部分内容可以暂时不用,没有完成部署验证,留待之后补全。
开放Web UI 端口1
2firewall-cmd --add-port=18080/tcp --permanent
firewall-cmd --reload
创建日志目录:1
/usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs dfs -mkdir /spark_logs
spark-defaults.conf
这部分配置的是 Spark 写入日志的信息。1
2
3spark.eventLog.enabled true
spark.eventLog.dir hdfs://weilu131:9000/spark_logs
spark.eventLog.compress true
spark-env.sh
1 | export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://weilu131:9000/spark_logs" |
启动日志服务器1
/usr/local/spark-2.4.0-bin-hadoop2.6/sbin/start-history-server.sh
访问日志服务器:http://192.168.0.131:18080
参考
[1] http://spark.apache.org/docs/latest/monitoring.html
[2] https://www.fwqtg.net/%E3%80%90spark%E5%8D%81%E5%85%AB%E3%80%91spark-history-server.html
[3] https://my.oschina.net/u/3754001/blog/1811243