摘要
Scrapy 是 Python 下一款非常好的爬虫框架,使用帮助快速实现爬虫。当爬虫数量较少时可以直接通过命令行的方式进行管理。但随着爬虫数量越来越多,版本不断更新,这时候就需要一些工具帮助我们进行爬虫管理了。而 Scrapyd 就是这样一个工具,其提供了一些基于 HTTP 的接口,帮助我们管理爬虫项目以及查看任务情况。
构建爬虫
首先使用 scrapy 构建一个简单的爬虫,示例中随便使用了一个地址,只是请求页面,不做具体的内容解析和处理。
安装 Scrapy
1 | pip install scrapy |
如果是在 Windowns 上安装的话,最好先安装以下两块内容:
Twisted-18.7.0-cp36-cp36m-win_amd64.whl
安装 twisted 编译好的版本,这个可以在如下网站下载:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
安装,进入下载文件所在目录,使用如下命令:1
pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl
pywin32-223.win-amd64-py3.6.exe
这个直接双击安装即可。
然后使用如下命令安装 scrapy:1
pip install scrapy
初始化 Scrapy 项目
scrapy 提供了一个非常方便的命令直接创建好一个爬虫项目的框架,进入一个你想放置爬虫项目的目录,执行以下命令:1
scrapy startproject IpSourceXici
命令执行完成后,会创建如下的一个目录结构:
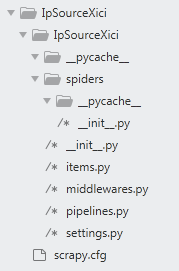
创建爬虫
在 spiders 目录中创建一个 py 文件,命名为 XiciSpider.py,其中添加以下内容:
1 | import scrapy |
这是一个非常简单的爬虫,仅仅访问了 URL,然后输出URL,没有进行任何处理。
配置爬虫
根据需要在 settings.py 文件中设置一些配置。由于我们只是作示例,因此对爬取速度、数量等要求都不高,因此我们最好不要对目标服务器产生过高的负载。
USER_AGENT
伪装浏览器
1 | USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' |
CONCURRENT_REQUESTS
设置最大的并行数量,这里仅设置一个即可。默认不设置是16个。
1 | CONCURRENT_REQUESTS = 1 |
DOWNLOAD_DELAY
设置随机停顿,即在爬取同一个源头的网页时,设置停顿时间 DOWNLOAD_DELAY 乘以一个随机种子(通过 RANDOMIZE_DOWNLOAD_DELAY 开启)。单位是秒。
1 | RANDOMIZE_DOWNLOAD_DELAY = True |
测试爬虫
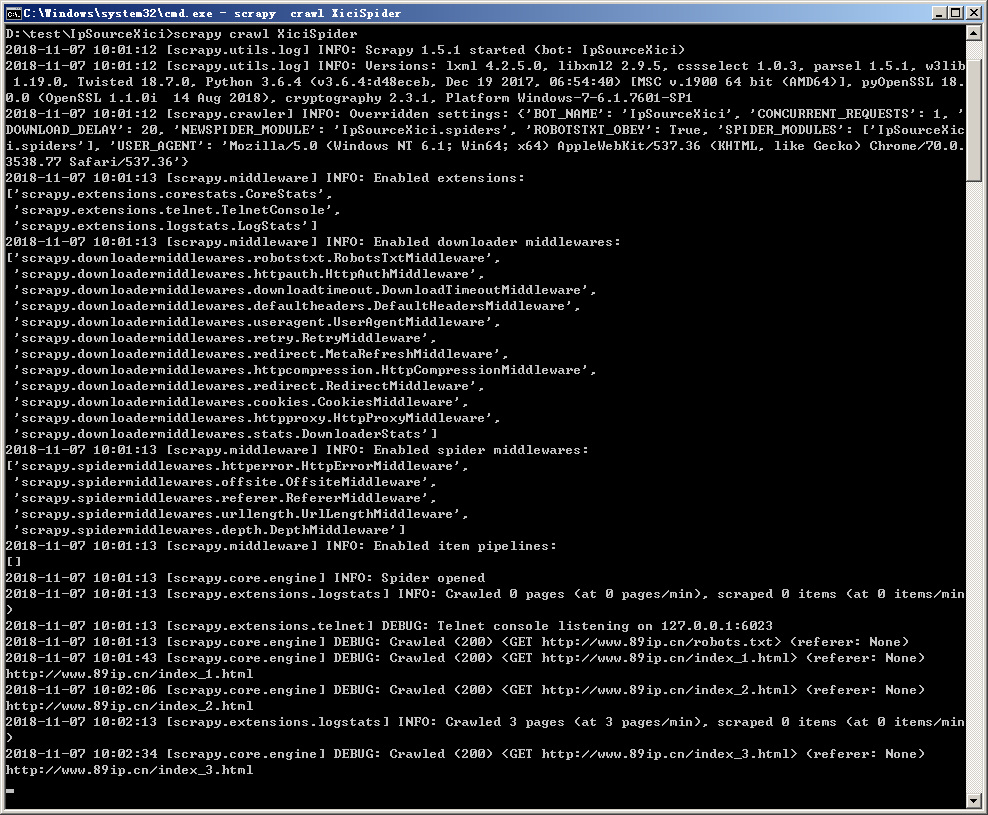
进入爬虫项目根目录,在这个示例中就是进入 IpSourceXici 目录,爬虫项目会构建两个 IpSourceXici 目录,进入最外层的一个即可,然后执行命令:
1 | scrapy crawl XiciSpider |
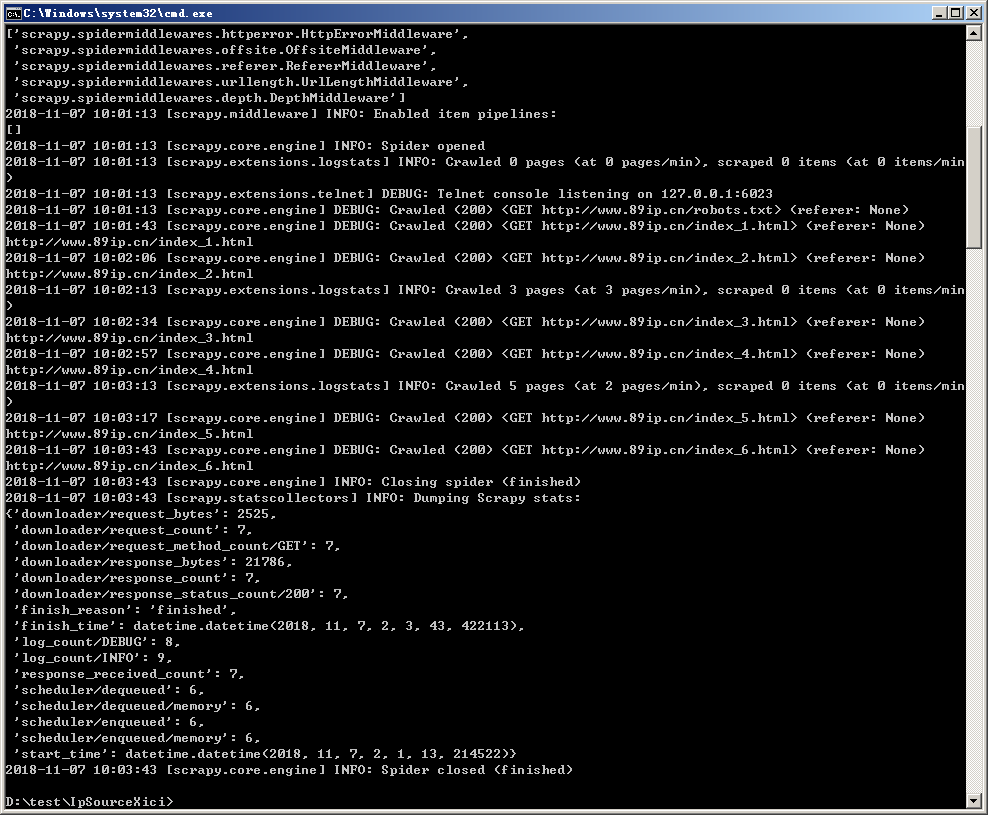
之后会输出如下内容,说明爬虫没有问题:
配置 Scrapyd 服务
安装 Scrapyd
直接使用命令安装:
1 | pip install scrapyd |
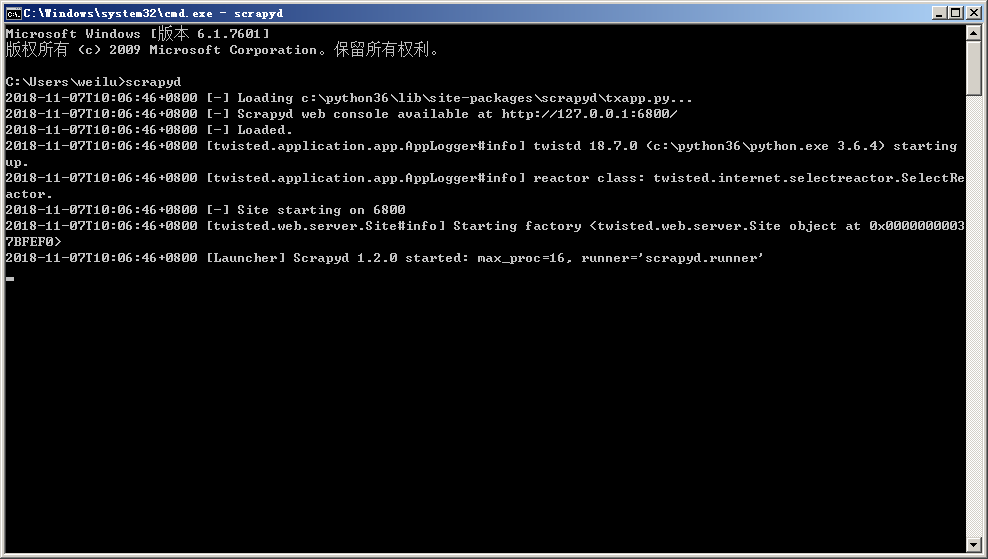
安装完成之后在命令行中输入命令启动 scrapyd 服务:
1 | scrapyd |
服务默认监听 6800 端口。
测试 Scrapyd 服务
直接在浏览器中访问地址:
可以查看到如下页面: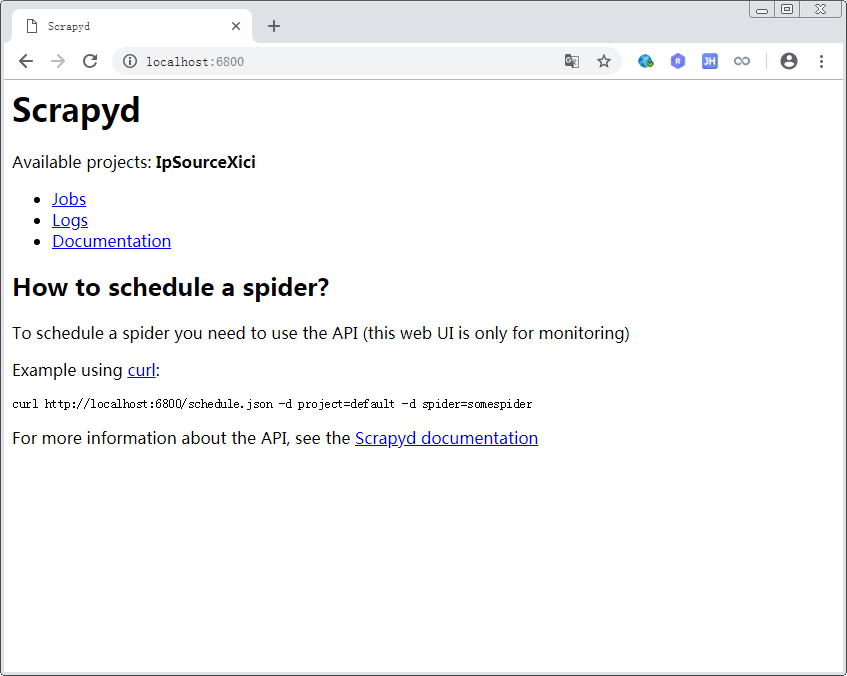
说明服务启动正常。当然,需要注意当前的 Available projects 后面应该是空的,因为我们还没有部署项目,这里是部署后的结果。
部署爬虫
部署爬虫可以使用专门的部署工具 scrapyd-deploy。
安装 Scrapyd-client
scrapyd-deploy 是 scrapyd-client 中的一个命令。
如果是在 linux 平台下安装,可以直接使用命令:
1 | pip install scrapyd-client |
不过这种方式在 windows 平台下安装会有问题,应该使用源码直接安装。
从 github 上下载:
https://github.com/scrapy/scrapyd-client/releases
解压后进入源码的根目录,使用命令安装:
1 | python setup.py install |
配置 scrapy.cfg
修改爬虫项目根目录下文件 scrapy.cfg,参考以下内容:
1 | [settings] |
主要是取消 url 的注释,以及设置 deploy 的 Name。
部署
进入爬虫所在目录使用命令:1
scrapyd-deploy XiciProxy -p IpSourceXici -v r1
如果得到如下反馈,应该就是部署成功了1
2
3
4Packing version r1
Deploying to project "IpSourceXici" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "weilu-PC", "status": "ok", "project": "IpSourceXici", "version":"r1", "spiders": 1}
验证
可以直接访问:
http://localhost:6800/
查看以有效的项目,同时可以使用如下接口对项目进行简单的管理。
参考接口
1 | #列出所有工程 |