摘要
记录一下 Hadoop 集群部署过程,简单的一拖三,包括 Hadoop 和 Yarn。
环境说明
配置环境准备四台机器,四台机器环境是 CentOS 7.5,IP和主机名配置如下:1
2
3
4192.168.0.131 weilu131
192.168.0.132 weilu132
192.168.0.135 weilu135
192.168.0.151 weilu151
注意:主机名不可以有下划线
前置配置
免密登录
生成密钥:1
ssh-keygen
这个会生成在 /root/.ssh/ 目录下,然后进入该目录,将公钥拷贝到其它两台机器上:1
ssh-copy-id -i id_rsa.pub root@weilu132
JDK环境
从本地将JDK包拷贝到机器上:1
2
3[root@weilu_125 packages]# scp jdk-8u181-linux-x64.tar.gz root@192.168.0.131:/usr/local/
root@192.168.0.131's password:
jdk-8u181-linux-x64.tar.gz 100% 177MB 11.1MB/s 00:15
解压到当前目录:1
tar -xvzf jdk-8u181-linux-x64.tar.gz
配置环境变量:1
vim /etc/profile
在其中末尾添加以下内容:1
2
3export JAVA_HOME=/usr/local/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后重新加载配置文件:1
source /etc/profile
检查配置结果:1
2
3
4[root@weilu_132 local]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
用相同的方法将其余两台机器也配置好。
防火墙配置
如果开启了防火墙,那么就需要开启以下端口
9000
这个端口是 Hadoop 集群中 NameNode 与 DataNode 通信的端口。
8031
这个端口是 Yarn 的 ResourceManager 与 NodeManager 通信的端口。
配置 Hadoop
下载:http://archive.cloudera.com/cdh5/cdh/5/
文件放置在 /usr/local/ 下,解压缩:1
tar -zxvf hadoop-2.6.0-cdh5.15.0.tar.gz
hadoop-env.sh
修改 hadoop 环境配置中的 JDK 配置:1
vim /usr/local/hadoop-2.6.0-cdh5.15.0/etc/hadoop/hadoop-env.sh
修改其中的 JAVA_HOME1
export JAVA_HOME=/usr/local/jdk1.8.0_181
core-site.xml
配置 NameNode 的URI:1
2
3
4
5
6<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://weilu131:9000</value>
</property>
</configuration>
hdfs-site.xml
配置 NameNode
配置 NameNode 在本地文件系统中存放内容的位置。首先创建目录:1
mkdir -p /home/hadoop/tmp/dfs/name
配置 DataNode
配置 DataNode 在本地文件系统中存放内容的位置。首先创建目录:1
mkdir -p /home/hadoop/tmp/dfs/data
这个目录是自己定义的。1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置 Yarn
yarn-site.xml
1 | <configuration> |
配置 MapReduce
mapred-site.xml
在每个节点上配置以下内容。
从模板中拷贝一份 mapred-site.xml 文件:1
cp mapred-site.xml.template mapred-site.xml
在新文件中添加以下内容:1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置从节点
slaves
在 slaves 文件中列出从节点的主机名或IP:
1 | weilu132 |
配置内存分配
默认的内存分配策略是基于至少 8G 内存的分配,如果所使用的机器内存少于 8G,就需要进行手动配置。
分配策略
一个 YARN 的 job 执行需要两类资源:
- 一个 Application Master(AM),负责监控应用以及在集群上协调分布的 executor;
- 若干 executor,由 AM 创建,实际 job 的执行者。
他们都运行在从节点的容器中。每个从节点运行一个 NodeManager 守护进程,负责在节点上创建容器。整个集群在一个 ResourceManager 的管理下,RM 负责在从节点上调度容器等。
整个集群正常工作,需要配置四类资源:
1、每个节点允许所有 YARN 容器占用的总的内存。
这个内存应该比其他所有的都大,否则应用程序无法正常执行。
这个值通过 yarn-site.xml 文件中的 yarn.nodemanager.resource.memory-mb 配置。
2、单个容器允许占用的内存
每个节点上可以有多个容器,单个容器需要配置允许的最大内存和最小内存。
通过 yarn-site.xml 文件中的 yarn.scheduler.maximum-allocation-mb 和 yarn.scheduler.minimum-allocation-mb 配置。
3、ApplicationMaster 允许的内存
这个值是在容器最大内存限制内的一个常数值。
通过 mapred-site.xml 文件中的 yarn.app.mapreduce.am.resource.mb 配置。
4、每个 map 和 reduce 操作允许的最大内存
通过 mapred-site.xml 文件中的 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb 配置。
这些配置之间的关系可以用下图表示:
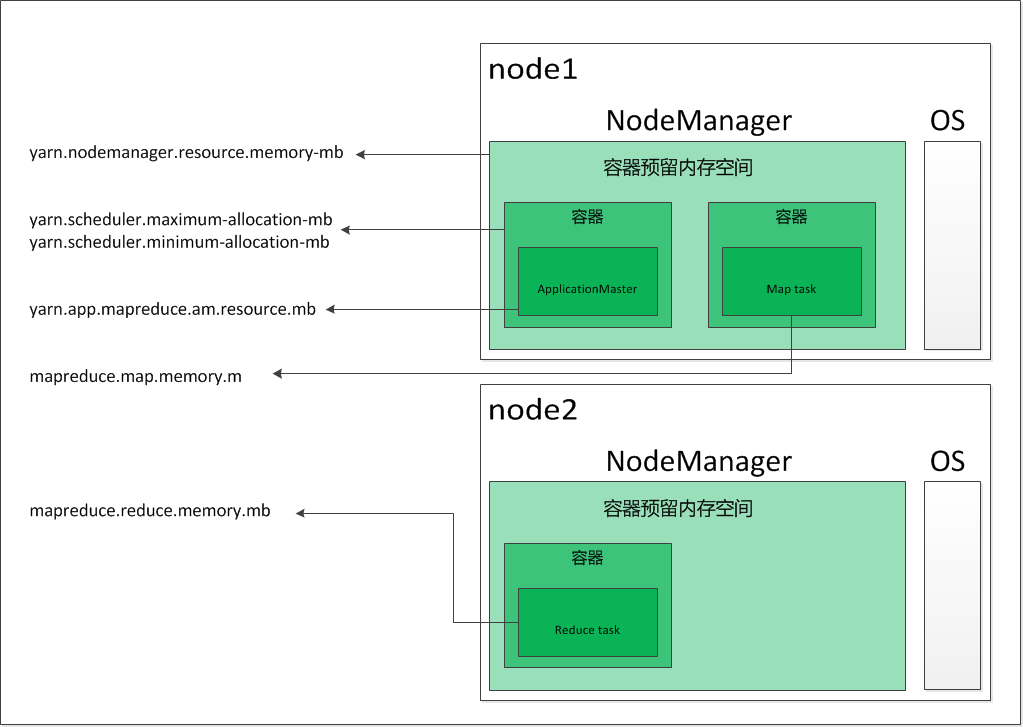
内存分配
| 属性 | 内存大小 |
|---|---|
| yarn.nodemanager.resource.memory-mb | 3000 |
| yarn.scheduler.maximum-allocation-mb | 3000 |
| yarn.scheduler.minimum-allocation-mb | 256 |
| yarn.app.mapreduce.am.resource.mb | 512 |
| mapreduce.map.memory.mb | 512 |
| mapreduce.reduce.memory.mb | 512 |
yarn-site.xml
在 yarn-site.xml 文件中添加以下内容:
1 | <property> |
mapred-site.xml
在 mapred-site.xml 文件中添加以下内容:
1 | <property> |
分发配置文件
注意,以上所有配置都是在 weilu131 上配置的,完成之后,将配置文件分发到其他几台机器上,每台机器的配置文件都是一模一样的,下面使用 scp 命令分发,以从节点文件为例:
1 | scp slaves root@weilu_132:/usr/local/hadoop-2.6.0-cdh5.15.0/etc/hadoop |
格式化文件系统
1 | [root@weilu_131 bin]# /usr/local/hadoop-2.6.0-cdh5.15.0/bin/hdfs namenode -format |
看到有这行输出表明格式化成功。
启动
1 | [root@weilu_131 sbin]# /usr/local/hadoop-2.6.0-cdh5.15.0/sbin/start-all.sh |
验证
验证进程
在 weilu131上:1
2
3
4
5[root@weilu131 sbin]# jps
3927 NameNode
4520 Jps
4254 ResourceManager
4111 SecondaryNameNode
因为在 weilu131 上部署了 NameNode 和 ResourceManager,因此使用 jps 命令应该能够看到这几个进程。
在其余几个节点上:1
2
3
4[root@weilu132 hadoop]# jps
1290 DataNode
1531 Jps
1391 NodeManager
因为其余几个节点上面只部署了 DataNode 和 NodeManager,因此使用 jps 命令应该能够看到这几个进程。
Hadoop Web 端验证
可以看到以下页面:
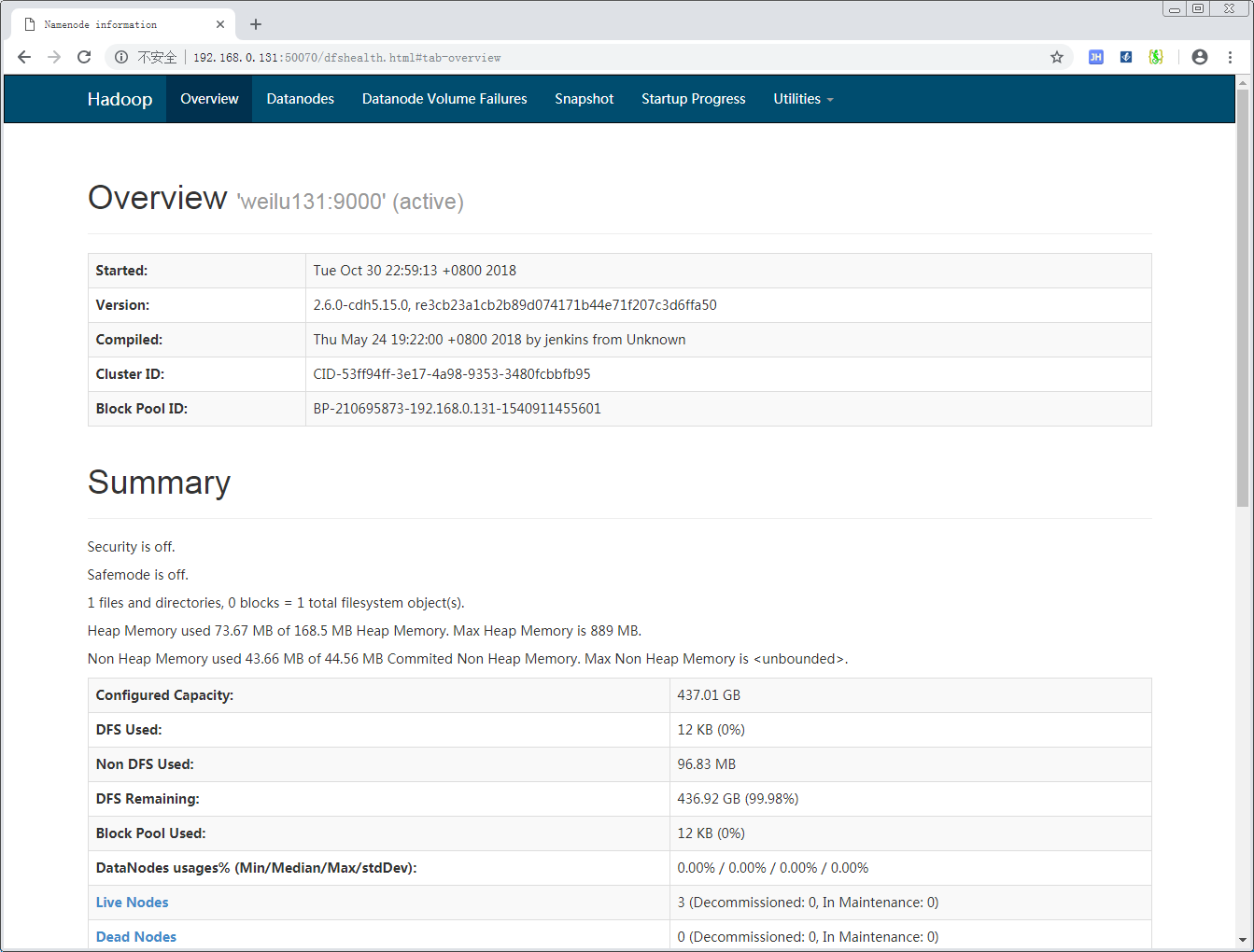
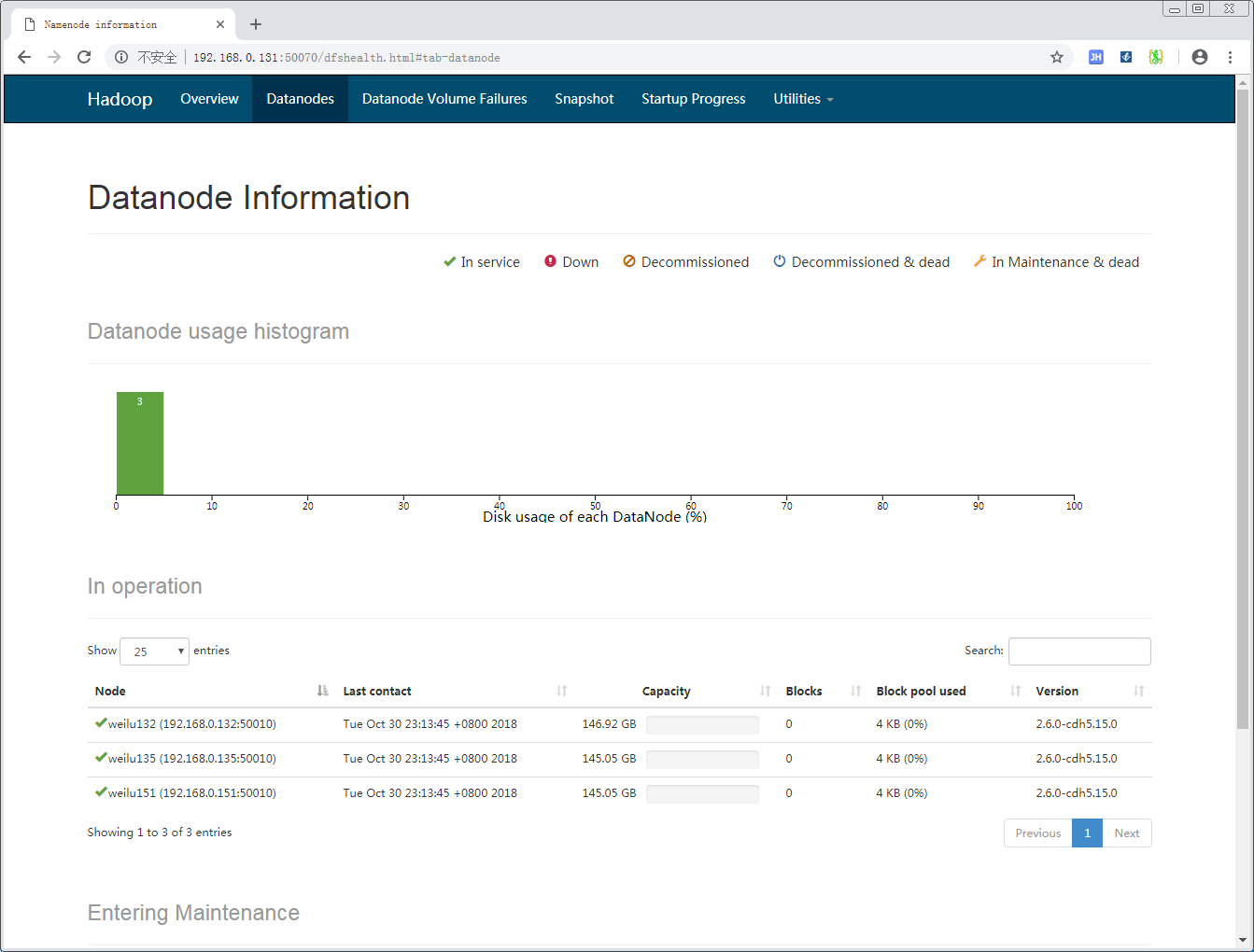
打开其中的 Live Node,可以看到目前存活的节点:
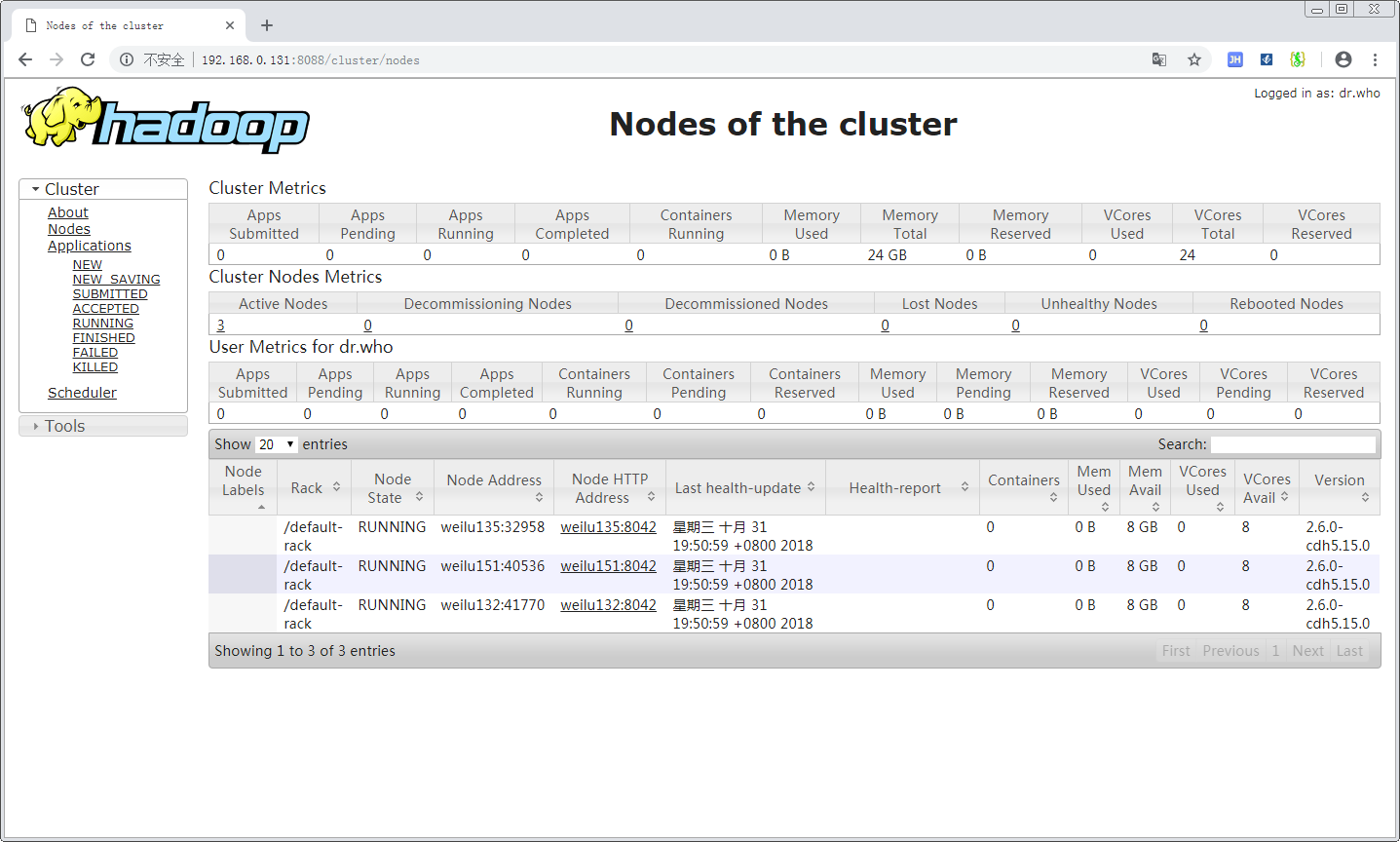
Yarn Web 端验证
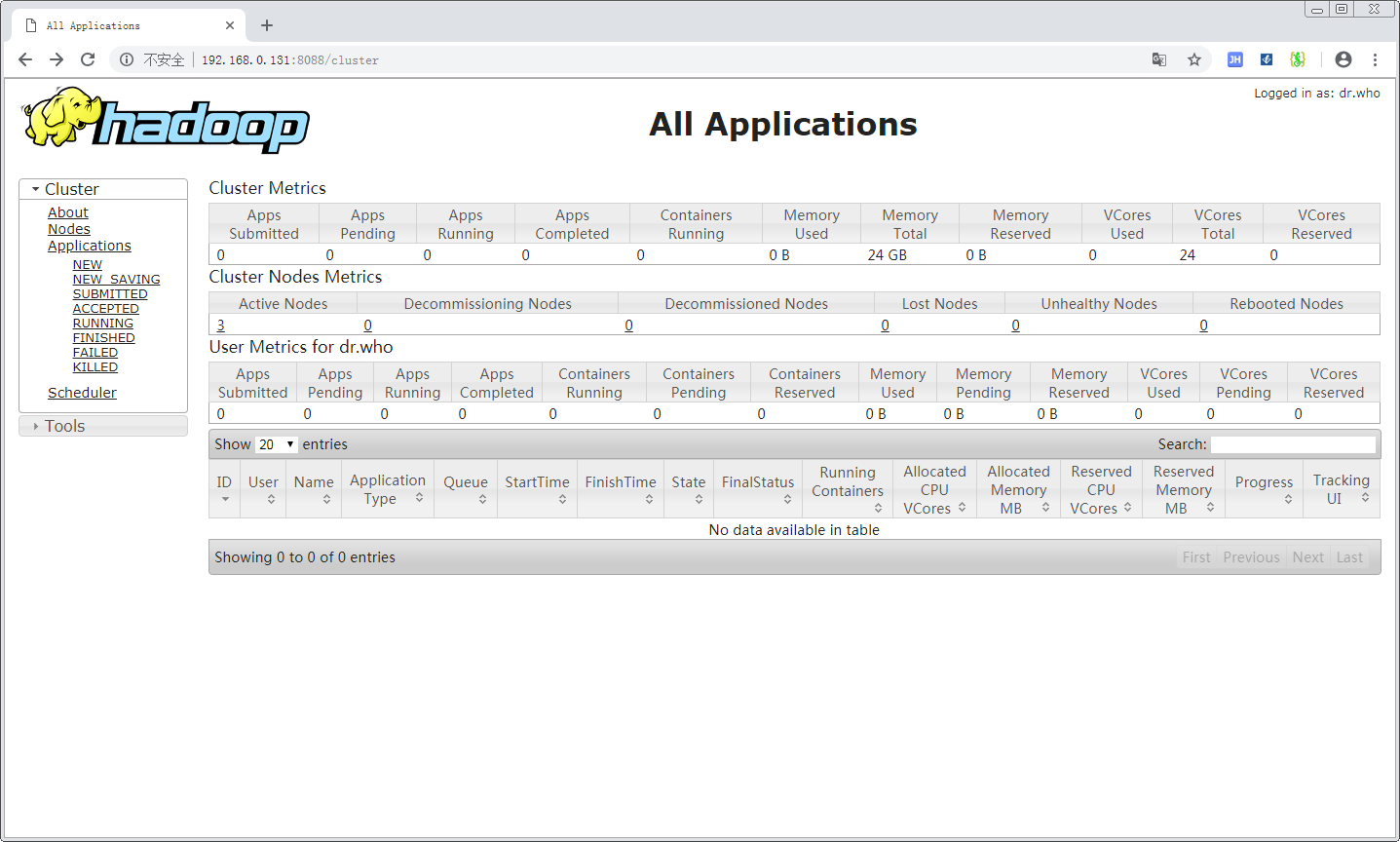
打开其中的 Active Node,可以看到目前存活的节点:
问题
集群正常启动 50070 页面显示没有 Live Node
NameNode 和 DataNode 都正常启动,但是访问 50070 页面发现检测不到任何节点。查看 DataNode 的日志,发现如下内容:1
2
3
42018-10-30 23:02:04,907 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: weilu131/192.168.0.131:9000. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-10-30 23:02:05,909 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: weilu131/192.168.0.131:9000. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-10-30 23:02:06,911 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: weilu131/192.168.0.131:9000. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2018-10-30 23:02:07,912 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: weilu131/192.168.0.131:9000. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
一种可能性是由于 NameNode 的防火墙开着,并且不允许访问 9000 端口,这样 DataNode 就没法向 NameNode 报告状态,将9000端口开启后,该问题马上解决了,验证了该猜想。
集群正常启动 Yarn 页面上看不到活动节点
查看 NodeManager 节点上的 Yarn 启动日志,可以看到以下错误信息:1
2
3org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.NoRouteToHostException: No Route to Host from weilu132/192.168.0.132 to weilu131:8031 failed on socket timeout exception: java.net.NoRouteToHostException: 没有到主机的路由; For more details see: http://wiki.apache.org/hadoop/NoRouteToHost
at org.apache.hadoop.yarn.server.nodemanager.NodeStatusUpdaterImpl.serviceStart(NodeStatusUpdaterImpl.java:215)
...
问题还是一样的问题,无法和 ResourceManager 节点进行通讯,yarn 使用的是 8031 端口,设置一下,然后重启集群。
参考
[1] https://www.linode.com/docs/databases/hadoop/how-to-install-and-set-up-hadoop-cluster/