摘要
学习 Spark 过程中记录的一些比较重要的概念。填充了一部分内容,另有一部分留空的,后续理解逐步加深后进一步补全和拓展。
基本概念和架构
基本概念
1. RDD
Resillient Distributed Dataset 弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
2. DAG
Directed Acyclic Graph 有向无环图,反应 RDD 之间的依赖关系
3. Executor
运行在工作节点(WorkerNode)上的一个进程,负责运行 Task
4. Application
用户编写的 Spark 应用程序
5. Task
运行在 Execotr 上的工作单元
6. Job
一个 Job 包含多个 RDD 及作用于相应 RDD 上的各种操作
7. Stage
是 Job 的基本调度单位,一个 Job 会分为多组 Task,每组 Task 成为 Stage,或者 TaskSet,代表一组关联的,相互之间没有 Shuffle 依赖关系的任务组成的任务集
运行架构
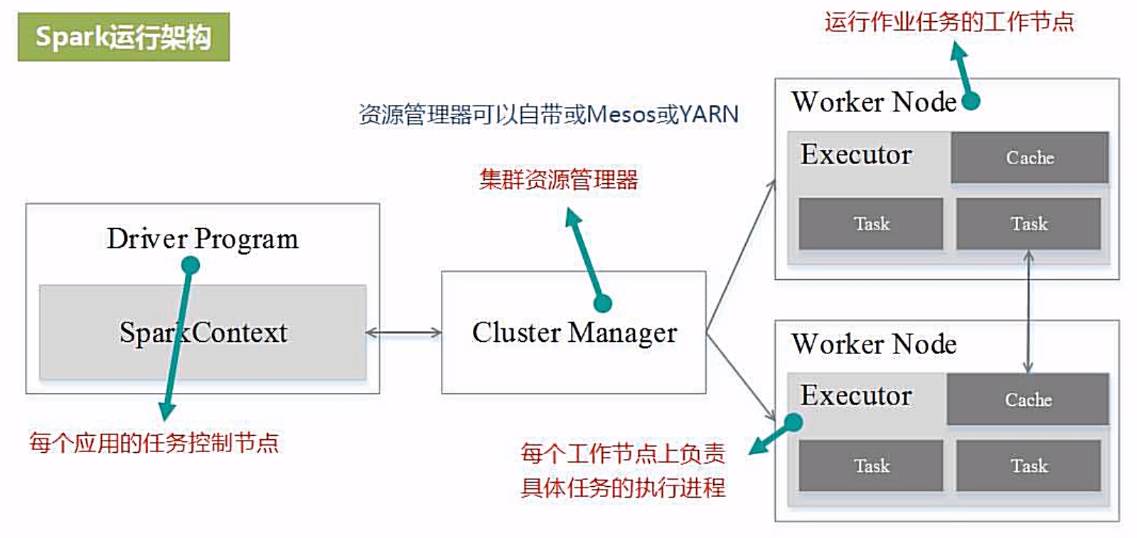
Spark有点:
1、利用多线程执行具体的任务,减少任务启动开销
2、Executor 中有一个 BlockManager 存储模块,结合内存和磁盘作为存储设备,减少 IO 开销
Spark 运行流程
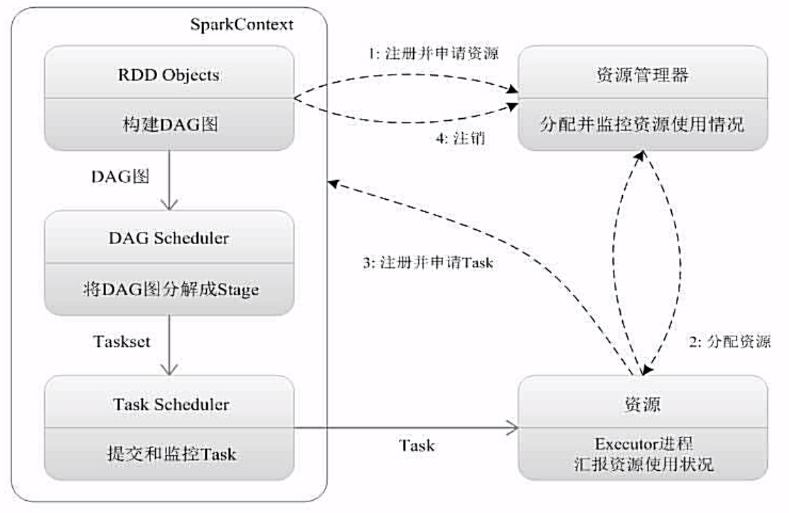
STEP 1
- 为应用构建基本的运行环境,由 Driver 创建一个 SparkContext 进行资源的申请、任务的分配和监控。
STEP 2
- 资源管理器为 Executor 分配资源,并启动 Executor 进程。
STEP 3
SparkContext 根据 RDD 的依赖关系构建 DAG 图,DAG 图提交给 DAGScheduler 解析成 Stage,然后把一个个 TaskSet 提交给底层调度器 TaskSchedule 处理。
Executor 向 SprakContext 申请 Task。
TaskScheduler 将 Task 分发给 Executor ,并提供应用程序代码
STEP 4
- Task 在 Excutor 上运行,把执行结果反馈给 TaskScheduler,然后反馈给 DAGScheduler,运行完成之后写入数据并释放资源。
Spark 运行特点
1、每个 Application 都有自己专属的 Executor 进程,并且该进程在 Application 运行期间一直驻留。Executor进程以多线程的方式运行 Task。
2、Spark 运行过程与资源管理器无关,只要能够获取 Executor 进程并保持通讯即可
3、Task 采用了数据本地性和推测执行优化机制
RDD
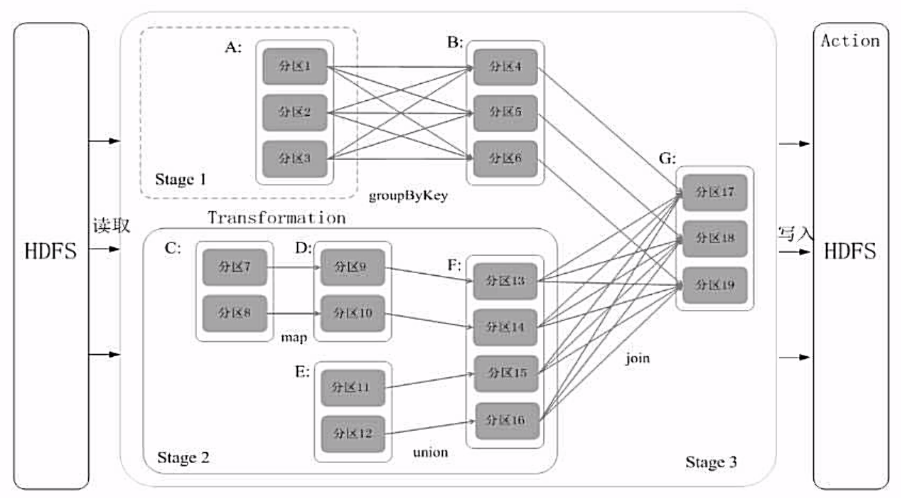
RDD 执行过程
1、RDD 读取外部数据进行创建
2、经过一系列转换(Transformation)操作,每次都会产生新的 RDD,提供给下一次转换操作使用
3、最后一个 RDD 经过“动作”操作进行转换,并输出到外部数据源
一般讲一个 DAG 的一系列处理成为一个 Lineage(血缘关系)
RDD 的依赖关系
窄依赖
1、一个父亲 RDD 的一个分区,转换得到一个儿子 RDD 的一个分区
2、多个父亲 RDD 的若干个分区,转换得到一个儿子 RDD 的一个分区
宽依赖
1、一个父亲 RDD 的一个分区,转换得到多个儿子 RDD 的若干个分区
Stage 划分
DAG 中进行反向解析,遇到宽依赖就断开,遇到债依赖就把当前 RDD 加入到 Stage 中。将窄依赖尽量划分在同一个 Stage 中,实现流水线计算。
RDD 基本操作
RDD 创建
从本地文件系统加载数据
1 | val lines = sc.textFile("file:///home/spark/mydata/word.txt") |
从分布式文件系统 HDFS 中加载数据1
val lines = sc.textFile("hdfs://weilu131:9000/mydata/word.txt")
从集合中创建 RDD
使用 sc.parallelize() 方法可以将数组转换为 RDD1
2val array = Array(1, 2, 3, 4, 5)
val rdd = sc.parallelize(array)
对于列表 List 同上。
RDD 操作
转换操作(Transformation)
filter(func)
筛选出能够满足函数 func 的元素,并返回一个新的数据集。1
2val lines = sc.textFile("hdfs://weilu131:9000/mydata/word.txt")
val res = lines.filter(line => line.contains("Spark")).count()
map(func)
将每个元素传递到函数func中,并将结果返回为一个新的数据集1
2val lines = sc.textFile("hdfs://weilu131:9000/mydata/word.txt")
val res = lines.map(line => line.split(" ").size).reduce((a,b) => if (a > b) a else b)
flatMap(func)
与 map 类似,但每个输入元素都可以映射到0或多个输出结果
groupByKey()
应用于(K,V)键值对数据集时,返回一个新的 (K, Iterable) 形式的数据集
reduceByKey(func)
应用于 (K, V) 键值对的数据集时,返回一个新的 (K, V) 形式的数据集,其中的每个值是将每个 key 传递到函数 func 中进行聚合。
行动操作(Action)
count()
返回数据集中的元素个数
collect()
以数组的形式返回数据集中的所有元素
first()
返回数据集中第一个元素
take(n)
以数组的形式返回数据集中的前 n 个元素
reduce(func)
通过函数 func(输入两个参数并返回一个值)聚合函数集中的元素
foreach(func)
将数据集中的每个元素传递到函数 func 中运行
惰性机制
对于 RDD 而言,每一次转换都会形成新的 RDD,但是在转换操作过程中,只会记录轨迹,只有程序运行到行动操作时,才会真正的进行计算,这个被称为惰性求值。
持久化
1 | val list = List("Hadoop", "Spark", "Hive") |
在两次行动操作中每次触发的转换操作都是相同的,为了避免重复计算,可以对第一次转换的过程进行持久化。
persist(MEMORY_ONLY)
将 RDD 作为反序列化对象存储于 JVM 中,如果内存不足,按照 LRU 原则替换缓存中内容。
persist(MEMORY_AND_DISK)
将 RDD 作为反序列化的对象存储在 JVM 中,如果内存不足,超出部分会被存储在硬盘上
cache()
persist(MEMORY_ONLY) 的快捷方式
unpersist()
手动把持久化的 RDD 从缓存中删除
1 | val list = List("Hadoop", "Spark", "Hive") |
分区
RDD 分区的一个分区原则是使得分区的个数尽量等于整个集群中的CPU核心数目
对于不同的 spark 部署模式而言,都可以使用 spark.default.parallelism 这个参数设置
在调用 textFile 和 parallelize 方法时候手动指定分区个数即可。
- 对于 parallelize 而言,如果没有在方法中指定分区数,则默认为 spake.deafault.parallelism。
- 对于textFile 而言,如果没有在方法中指定分区数,则默认为 min(defaultParallelism, 2),其中,defaultParallelism 对应的就是 spark.default.parallelism
- 如果时从 HDFS 中读取文件,则分区数为文件分片数(比如,128MB/片)
textFile
1 | sc.textFile(path, partitionNum) |
parallelize
1 | sc.parallelize(array, 2) // 设置两个分区 |
通过转换操作得到新的 RDD 时,直接调用 reparation 方法
自定义分区1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import org.apache.spark.{Partitioner, SparkContext, SparkConf}
class UserPartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
key.toString.toInt % 10
}
}
object ManualPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
val sc = new SparkContext(conf)
val data = sc.parallelize(1 to 5, 5)
val data2 = data.map((_, 1))
val data3 = data2.partitionBy(new UserPartitioner(10))
val data4 = data3.map(_._1)
data4.saveAsTextFile("hdfs://weilu131:9000/test/output")
}
}
Pair RDD(键值对 RDD)
创建 PairRDD
1 | val list = List("Hadoop", "Hive", "HBase", "Spark", "Sqoop", "Spark") |
打印内容:1
2
3
4
5
6(Hadoop,1)
(Hive,1)
(HBase,1)
(Spark,1)
(Sqoop,1)
(Spark,1)
reduceByKey(func)
key 相同,将值按照传入逻辑计算1
2
3
4
5
6
7
8
9
10
11
12
13val list = List("Hadoop 2", "Spark 3", "HBase 5", "Spark 6", "Hadoop 1")
val rdd = sc.parallelize(list)
val split = (line : String) => {
val res = line.split(" ")
(res(0), res(1).toInt)
}
val pairRdd = rdd.map(split)
pairRdd.collect().foreach(println) // 打印测试:1
val res = pairRdd.reduceByKey((a,b) => a+b)
res.collect().foreach(println) // 打印测试:2
打印结果:1
2
3
4
5
6
7
8
9
10
11// 第一次
(Hadoop,2)
(Spark,3)
(HBase,5)
(Spark,6)
(Hadoop,1)
// 第二次
(Spark,9)
(HBase,5)
(Hadoop,3)
groupByKey()
key 相同,将值生成一个列表1
2
3
4
5
6
7
8
9
10
11
12
13val list = List("Hadoop 2", "Spark 3", "HBase 5", "Spark 6", "Hadoop 1")
val rdd = sc.parallelize(list)
val split = (line : String) => {
val res = line.split(" ")
(res(0), res(1).toInt)
}
val pairRdd = rdd.map(split)
pairRdd.collect().foreach(println) // 打印测试:1
val res = pairRdd.groupByKey()
res.collect().foreach(println) // 打印测试:2
打印结果:1
2
3
4
5
6
7
8
9
10
11// 第一次
(Hadoop,2)
(Spark,3)
(HBase,5)
(Spark,6)
(Hadoop,1)
// 第二次
(Spark,CompactBuffer(6, 3))
(HBase,CompactBuffer(5))
(Hadoop,CompactBuffer(1, 2))
keys、values
仅仅把 PairRDD 中的键或者值单独取出来形成一个 RDD
sortByKey()
1 | val list = List("Hadoop 2", "Spark 3", "HBase 5", "Spark 6", "Hadoop 1") |
打印结果:1
2
3
4
5
6
7
8
9
10
11
12
13# 1
(HBase,5)
(Hadoop,2)
(Hadoop,1)
(Spark,6)
(Spark,3)
# 2
(Spark,3)
(Spark,6)
(Hadoop,1)
(Hadoop,2)
(HBase,5)
mapValues(func)
对 PairRDD 中的每个值进行处理,不影响 key.
join
将两个 PairRDD 根据 key 进行连接操作
combineByKey
共享变量
主要用于节省传输开销。
当Spark在集群的多个节点上的多个任务上并行运行一个函数时,它会吧函数中涉及到的每个变量在每个任务中生成一个副本。但是,有时需要在多个任务之间共享变量,或者在任务和任务控制节点之间共享变量。
为满足这种需求,Spark提供了两种类型的变量:广播变量(broadcast variables)和累加器(accumulators)。
广播变量用来把变量在所有节点的内存之间进行共享;
累加器则支持在所有不同节点之间进行累加计算(比如计数、求和等)
广播变量
允许程序开发人员在每个机器上缓存一个只读变量,而不是在每个机器上的每个任务都生成一个副本。
Spark的“行动”操作会跨越多个阶段(Stage),对每个阶段内的所有任务所需要的公共数据,Spark会自动进行广播。
可以使用 broadcast() 方法封装广播变量1
2
3val broadcastVar = sc.broadcast(Array(1, 2, 3))
println(broadcastVar.value)
累加器
Spark 原生支持数值型累加器,可以通过自定义开发对新类型支持的累加器。
longAccumulator & doubleAccumulator
Spark 自带长整型和双精度数值累加器,可以通过以上两个方法创建。创建完成之后可以使用 add 方法进行累加操作,但在每个节点上只能进行累加操作,不能读取。只有任务控制节点可以使用 value 方法读取累加器的值。
1 | val accum = sc.longAccumulator("OneAccumulator") |
数据读写
文件系统数据读写
读写本地文件1
2
3
4val aFile = sc.textFile("file:///home/spark/somewords.txt")
// 保存时会生成一个目录,内容被跌倒这个目录中
aFile.saveAsTextFile("file:///home/spark/something.txt")
读写HDFS文件1
2
3
4val aFile = sc.textFile("hdfs://weilu131:9000/home/spark/somewords.txt")
// 保存时会生成一个目录,内容被跌倒这个目录中
aFile.saveAsTextFile("hdfs://weilu131:9000/home/spark/something.txt")